This article will show you how to change the configurations and schema while creating a new dataset from CSV or JSON lines files
Where to find and change configuration?
The Engine will automatically detect the configurations for reading your data.
By default, configurations are hidden. To view the set of configurations, click on "Show Configurations"
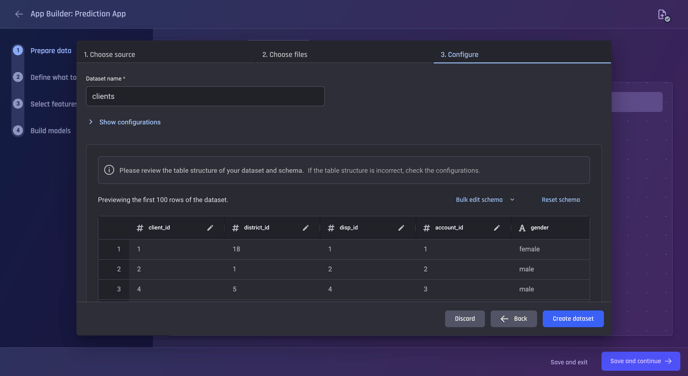
Once the desired change has been made to the configurations, click on "Apply Changes". This will:
-
Save the configuration changes.
-
Re-generate the preview based on the current configurations.
Caution: If you made changes to the configurations, you will not be able to proceed to the next step without applying the changes.
If you would like to revert to the automatically generated configurations by the Engine, select “Reset to defaults” button.
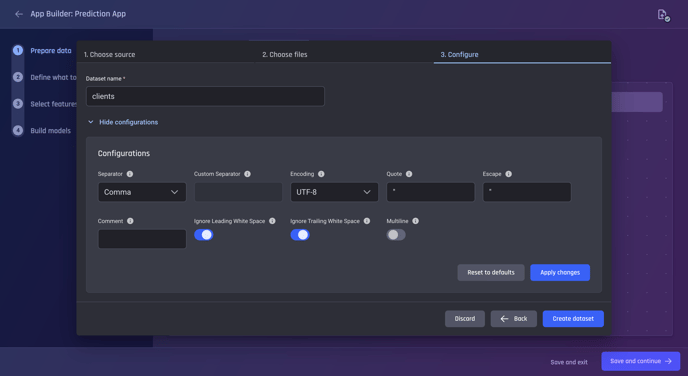
Where to find and change the schema (column datatype)?
In step 3, the final step of the “create new dataset” process, users can modify the dataset's schema:
-
Change the datatype for individual columns in the dataset
By default, the Engine automatically detects the most suitable datatype for each column. Users can opt to change the individual column's datatype by selecting the Edit icon in the corresponding column.
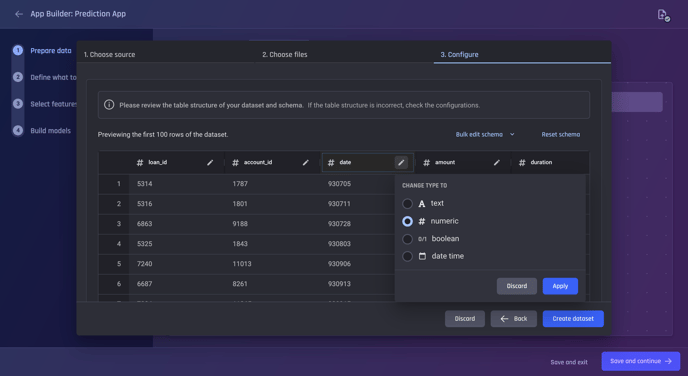 Change the data type of a column by clicking on the edit icon
Change the data type of a column by clicking on the edit icon
The Engine also detects the format of datetime columns on a per-column basis, and lets users edit the format if needed:
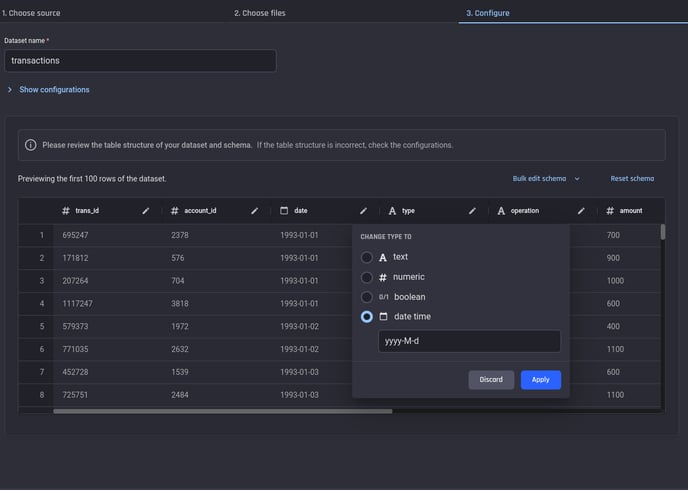
-
Change the data types of many columns in the dataset at the same time
You can choose to bulk edit the data type of different columns by selecting the “Bulk Edit Schema” button.
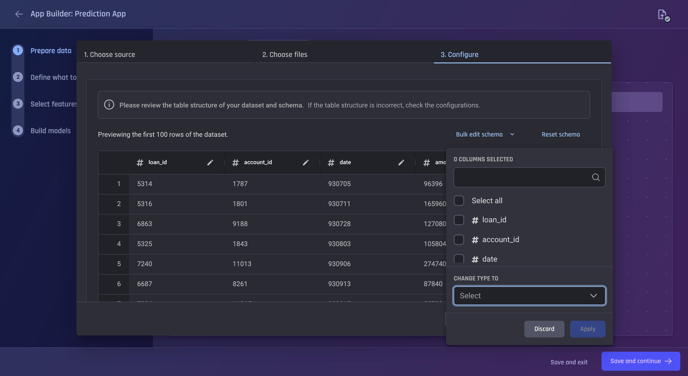 The “Bulk edit schema” function allows the user to edit the dataset’s schema in bulk
The “Bulk edit schema” function allows the user to edit the dataset’s schema in bulk