This article outlines the datasets required to use the transaction option in the AI & Analytics Engine's customer churn template.
To build and use a customer churn model when the transactional option is selected, you’ll need a customer transaction dataset. This dataset should include details about every transaction that happened over a sufficient period of time, identifying the customer who made the transaction, the amount, and the date.
💡The required minimal period of time for the recorded transactions is determined by the AI & Analytics Engine based on the given app configuration. It’s displayed in the Add data stage of the App building pipeline.
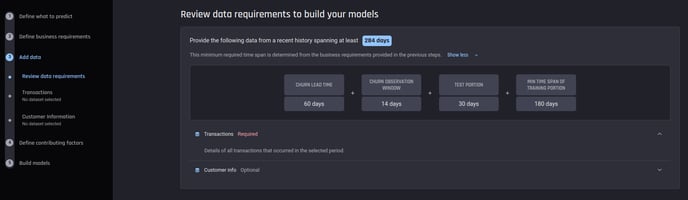 Add data stage of the App builder pipeline
Add data stage of the App builder pipeline
In the example above, the minimal required timespan for the recorded transactions is 284 days. (Or about 9 months).
-
180 days of transactions will be used for training
-
60 days as lead time
-
14 days to determine the labels for the 180-day period
-
30 days to serve as a separate test set
The Engine uses this information to build a predictive machine learning model, that creates predictions that will indicate the likelihood of churn for each active customer. Therefore, it's mandatory to provide a historical transactions dataset to be able to use the transactional churn option. Each row of this dataset needs to show a unique transaction. The data must include the following three columns:
-
A column that shows the customer ID
-
A column with the transaction date and time
-
A column containing the transaction amount
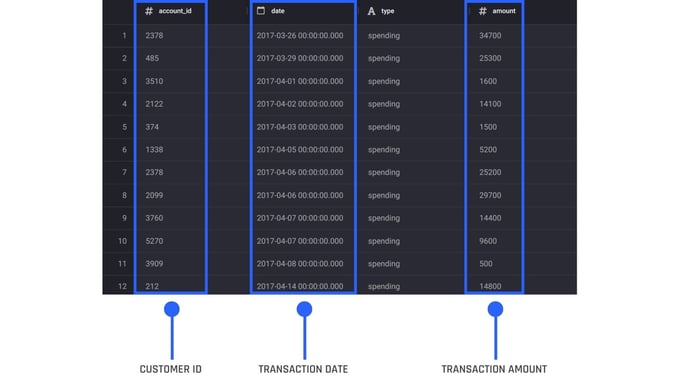
The following convention applies for the transactions amounts:
Only spend and refund transactions should be included. Exclude all other types of transactions, including, but not limited to: credit-card balance repayments, service fees, or incentives offered to customers in the form of credits to their account.
For the spending and refunds:
-
Spending by customers: Must be positive
-
Refunds: Must be negative
If the transaction column does not adhere to the format above, the data must be wrangled externally or using a recipe in the AI & Analytics Engine to transform the transaction amounts to the required format, before importing into the template.
Additionally, a customer Information dataset can optionally be included in the template. This dataset must contain one row per customer ID capturing their:
-
Biographic/demographic profile information: Eg. age, place of birth, current employment status, education level, residential address, household size, annual income, etc.
-
Business-specific information: Eg. customer type, sign-up date, ongoing subscription cost, etc.
This dataset must have a column that contains the customer ID - the same ones in the customer identifier column of the customer transactions dataset.
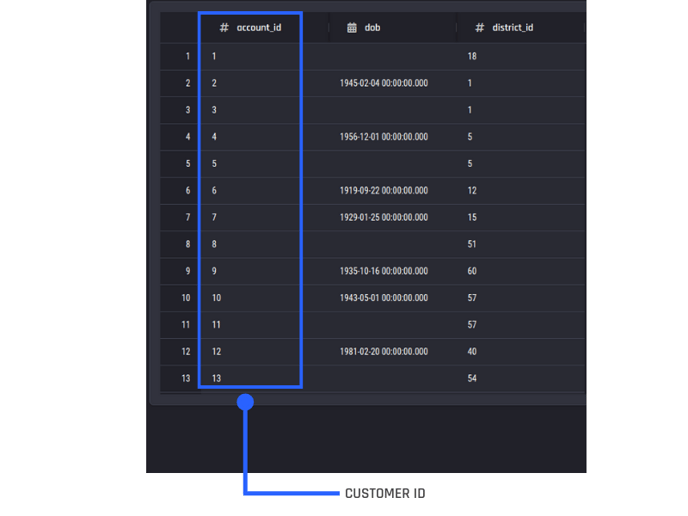 Customer information data
Customer information data