This article defines algorithms in the AI & Analytics Engine in the context of classification and regression machine learning problem.
An algorithm is a set of instructions for solving logical and mathematical problems, or for accomplishing some other task (source: Wikipedia)
In the context of machine learning, there various types of algorithms. This includes dimensionality reduction algorithms or algorithms used to identify similarities between records in datasets, etc.
In the context of the AI & Analytics Engine, the main algorithms cover the 2 following domains:
-
Supervised learning: Classification and regression.
-
Unsupervised learning: Clustering.
The family of supervised learning algorithms are algorithms that learn the relationship between the features, and the target variable from the data they are exposed to, in such a manner that it can reliably estimate the latter from the former.
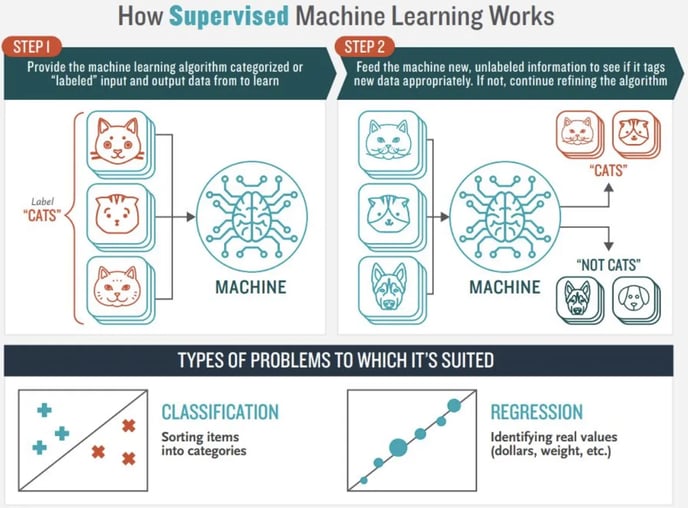 How does supervised learning work? (Image by Jorge Leonel via Medium)
How does supervised learning work? (Image by Jorge Leonel via Medium)
On the other hand, in the unsupervised learning family of algorithms, there is no target variable.
Clustering algorithms belong to this family. These algorithms are given an input dataset and output a grouping of similar items within the dataset.
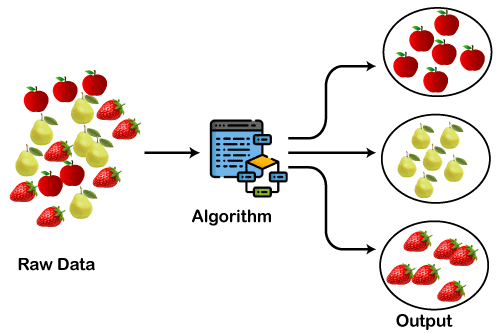 (Image by Moez All via Datacamp)
(Image by Moez All via Datacamp)
Algorithms in the context of the AI & Analytics Engine
”Building a model” is one of the stages when creating an app in the AI & Analytics Engine, and refers to the process of “fitting” the model. This fitting process depends on the type of algorithm.
-
In the context of supervised learning, fitting means learning the function that maps the inputs to outputs.
For example, you might want to predict house prices given the house features.-
An regression algorithm called “linear regression” will perform the fitting using an algorithm called gradient descent.
-
Another regression algorithm called “decision tree regressor” performs fitting using a different method called “decision tree learning”.
-
-
In the context of clustering it means finding the groups of similar items, so, in the future, any new item could be associated to one of the groups we discovered.
The AI & Analytics Engine supports many algorithms from each family and automates the entire “build” stage so that the users do not need to go into the technical details of building models and instead can focus on solving their problems at hand.
For more information about the available algorithms, read this article.