This article describes what a feature and feature set is in machine learning, and how to create it in the AI & Analytics Engine.
What is a feature?
In machine learning, a feature is a characteristic or measurable property of the data. Features are used as input for a model to make predictions or find clusters.
🎓 To learn more about the other machine-learning problems, read what machine learning problems does the Engine tackle
For example, in a dataset for house price prediction, features could include the number of bedrooms, the suburb where the house is located, the size and the year when it was built. In the Engine, each feature is associated with a type that indicates the “meaning” of the feature and also determines how it can be pre-processed before model training.
🎓 The Engine supports three feature types: Numeric, Categorical and Text. To learn more about feature types, read what is feature type.
To learn how features are pre-processed in the Engine, read how are features pre-processed for machine learning algorithms
Why is feature selection important?
Feature selection is an important step in building machine-learning models, especially when the datasets have a large number of dimensions. It involves the process of selecting only the relevant and informative features to predict a target or identify similar items from the ML-ready dataset. It helps reduce the noise contained in the original data, leading to more effective and efficient models.
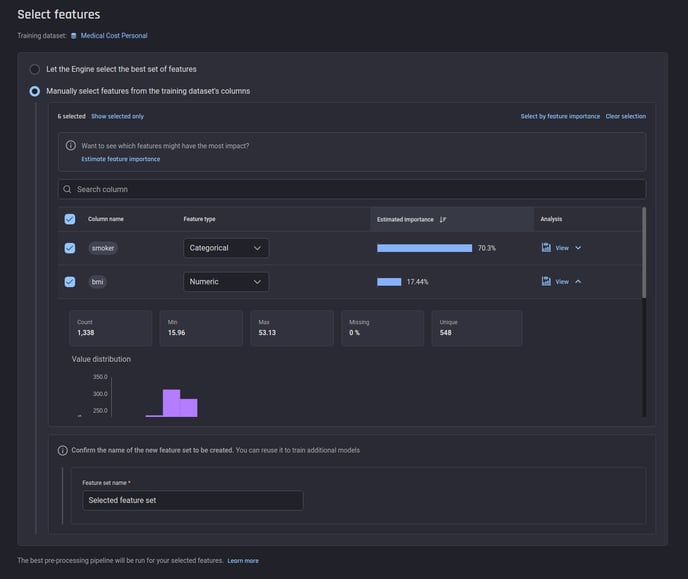
How can you select features in the Engine?
The Engine supports two ways of feature selection:
-
Automatically choosing the best features with a specified total estimated importance threshold
-
Manually choosing from the features available in the dataset
 Options for feature selection
Options for feature selection
Option 1 is normally used when the number of features is large and the domain knowledge is insufficient or under an exploratory phase; Option 2 fits the situations where the domain knowledge is strong, the number of features is not large, or the explainability of each feature used in model training is crucial. Both options are supported by the feature importance estimation. In both options, you can specify one or more columns to be entirely excluded while the Engine analyzes your dataset to determine the most important columns. This is useful in two scenarios:
-
Target leakage: In this scenario, you have a proxy of the target column that you will actually not be having in a real deployment. You may have created such columns to explore and analyze your training dataset. For instance, in a model predicting rainfall, a column Total Rainfall Next Day might be a proxy for your target, but it should be removed as it will not be available in real deployment.
-
Irrelevant columns: You may have irrelevant columns such as customer ID, product description, URLs, etc. that are irrelevant to your prediction problem. Including such columns can slow down the feature selection process as such irrelevant columns can be computationally expensive to analyze.
💡 The Engine uses Generative AI to smartly detect and suggest columns to be excluded from consideration as candidate features.
Excluding such columns provides a way for you to ensure that only relevant features are considered.
🎓 For more information on estimated feature importance scores, read what are estimated feature importance scores in feature selection.
What is a feature set?
The result of feature selection is a feature set, which is a subset of features deemed most relevant for the machine-learning task. A well-selected feature set simplifies the model, reduces the time in computation and improves model performance. In the Engine, a feature set can be re-used to train different models, which makes it consistent in comparing algorithms. Re-using feature sets also reduces additional computation and human effort especially when feature selection is at the experimental stage.