This article will explain the typical flow from data to trained and evaluated models on the AI & Analytics Engine
NOTE: This specifically applies to classification & regression problem types
The flow from dataset creation to the evaluation of trained models is as follows:
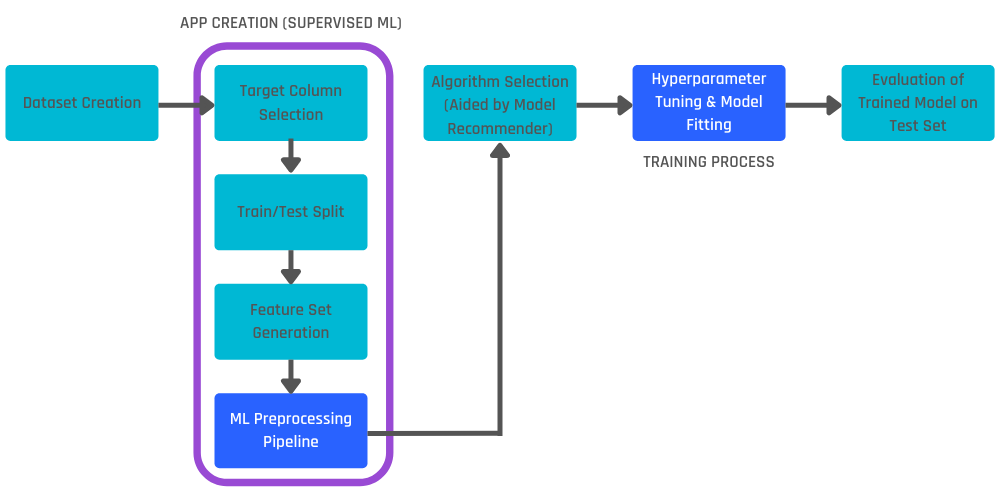
In this article, we will explain the two steps highlighted in dark blue in the above illustration:
-
ML Preprocessing Pipeline: Pre-processing the input data into numeric data, using only the columns from the feature set selected while creating the model.
-
Hyperparameter Tuning and Model Fitting: Finding the best combination of hyperparameters for the algorithm selected by the user to train the model, and fitting the final model on the train portion using the best hyperparameters found.
In the Engine, both steps are automated to save time for users. Let us explain these two steps in further detail.
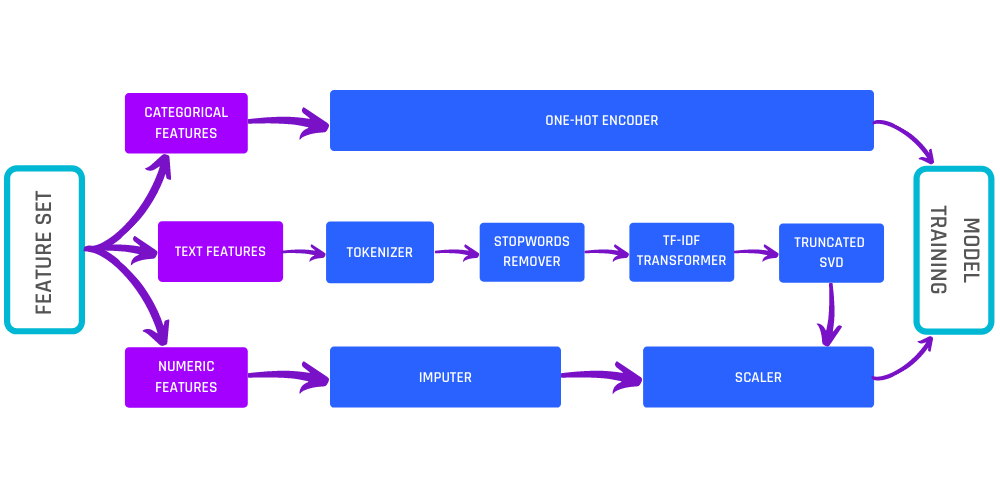
ML Preprocessing Pipeline
This step is necessary since model-training algorithms typically require all inputs to be numeric, all values to be filled and none of them missing, and values in all input columns to be in the same scale/range. None of these are possible in real-world datasets. This gap is bridged by the ML preprocessing pipeline. Here, categorical and text features in real-world datasets are converted to numbers using techniques such as One-Hot Encoding and the TF-IDF transformer, missing values in the data are imputed using mean/median values, and all numeric features are scaled using a transformation to be roughly in the same range.
Hyperparameter Tuning
Hyperparameter tuning is typically required before model fitting to ensure that the resulting model is good at making predictions on new data.
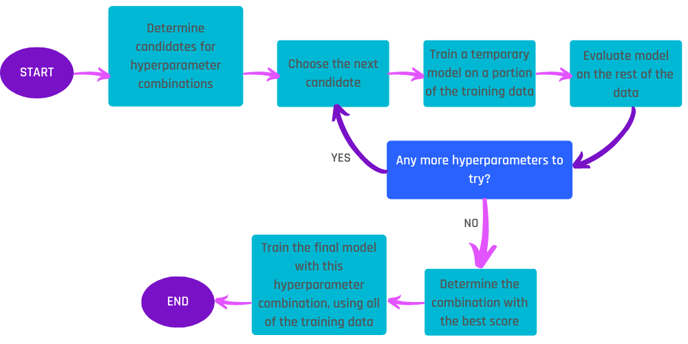
First, a candidate set of hyperparameter combinations is determined, for example, by considering a grid of possible values for each tunable hyperparameter in the algorithm. This approach is known as “Grid Search” and is used in the current implementation of the AI & Analytics Engine.
The process then involves evaluating each of these combinations to find the best one. This is achieved by running a validation process on the train portion, explained below.
The process of validation enables us to evaluate how well a model will perform on new data if trained with a certain combination of hyperparameters. By doing so, the test portion is still reserved for evaluating the final model.
The process of validation works as follows: For each candidate combination of hyperparameters, we train a temporary model on one part of the training portion. We use the remaining training portion to validate the resulting model. This is done by obtaining its predictions on the validation part and comparing it with the actual values in the target column. The desired evaluation metric can then be computed. This process may be repeated using different partitions of the training portion and averaging the evaluation metric to get a more reliable measure.
There are two popular ways to perform validation on the train set: K-fold cross-validation, and train-validation split.
In K-Fold Cross Validation, the training portion is first split into K “folds”. Think of this as cutting it equally into K pieces, as shown in the diagram below. Taking one fold at a time, we use the remaining K-1 folds to train a temporary model using the candidate hyperparameter combination. We then evaluate the model using the current fold (which was not included in the model’s training) to get a performance measure as a “score”. For K folds, this results in K temporary trainings and K scores. The average of these K scores is taken as the “score” associated with the candidate hyperparameter configuration. This process is repeated for each hyperparameter configuration to be evaluated.
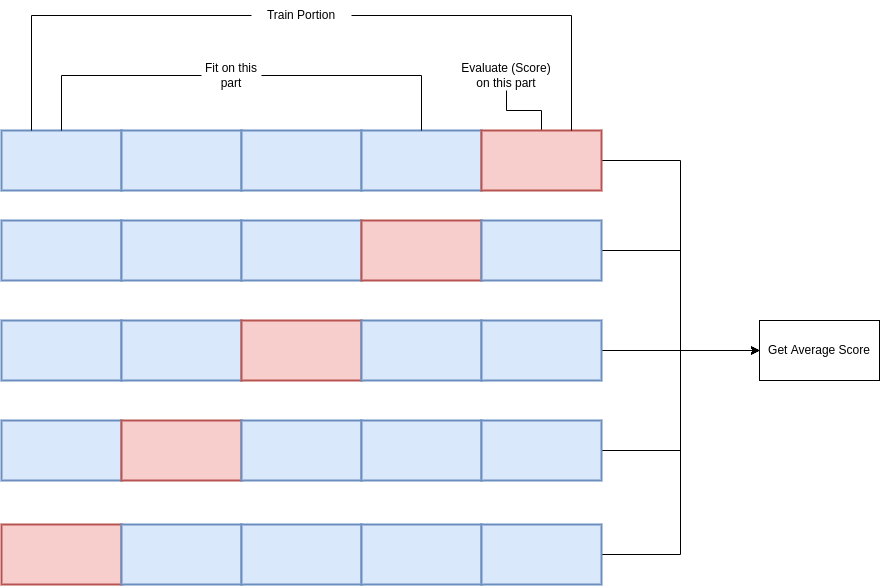
K-fold Cross Validation is the preferred method for tuning model hyperparameters when the dataset is small. On the AI & Analytics Engine, a default value of K = 5 is used for the number of folds.
For large datasets, a single Train-Validation Split would suffice. The model is trained on the initial portion, which is typically larger, and validated on the remaining portion, which is typically smaller. This provides the score for the given hyperparameter configuration.
Fitting the Final Model
Once the best combination of hyperparameters is found, the final model is trained using the whole training portion of the dataset with the algorithm’s hyperparameters set to these values.