This article explains clustering as a term and as a concept within the AI & Analytics Engine: Clustering is a set of techniques in Machine Learning that can automatically discover groups of similar entities from a dataset and segment it accordingly.
Clustering is a set of techniques in machine learning
Clustering can automatically discover groups of similar entities from a dataset and segment it accordingly.
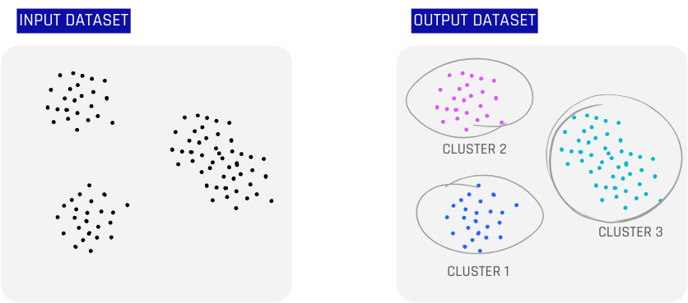
💡How many clusters are there in the input dataset on the left? A good clustering technique will produce results as seen on the right side. Colours indicate the cluster ID assigned to each entity in the data.
Unlike classification and regression where the goal is to build a model that predicts a specified column in the dataset, there is no column to predict in clustering. Instead, clustering is used to discover and describe patterns in data by analyzing similarities to find the most coherent groupings automatically.
Examples of clustering
Clustering thus provides a powerful way to generate highly valuable and actionable insights from datasets of any size. Applications of clustering in the real world include:
-
Demographic and behavioural segmentation of customers
-
Product recommendation
-
Market research
-
Biological data analysis
Clustering in the AI & Analytics Engine
In the AI & Analytics Engine, you can build clustering models in the the app builder pipeline, where you’ll need to upload your data and choose the column to be considered while determining the similarity between items. The Engine will automatically provide recommendations for the algorithm and configurations to use based on output quality and model training time.
💡 Build a clustering model in the AI & Analytics Engine by following the guide How to build a clustering pipeline.