Train/test split is an important concept in the training and evaluation of classification and regression models. When done correctly it can lead to accurate estimates of the model’s prediction quality for future data.
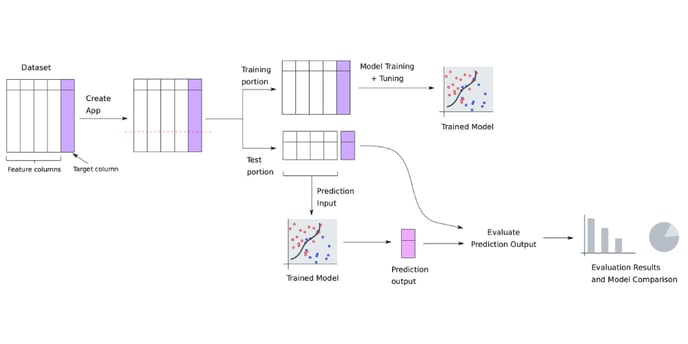
Train/test split is an important concept in the training and evaluation of classification and regression models, where either a categorical or continuous column/variable is to be predicted from the other columns/variables in the dataset. The dataset is split into two portions called “train” and “test” portions. The train portion is presented to the model as labeled data at the time of training so it can learn from the examples in it to make future predictions. Once a model is trained, it is made to predict for the test portion using only the knowledge of the data in the other columns.
There are two split methods commonly used: random and time-based.
-
For the random split, a split ratio is needed to define how much of the data is used for training, and how much for the test portion. It is usually presented as a percentage value. For example, 80% data for training implies an 80-20 split, where 20% of the data is used for the test portion.
-
For the time-based split, a split time-point needs to be specified along with the time-index column to separate the test portion data in the later period from training data in the early period.
The train/test split on the AI & Analytics Engine
On the AI & Analytics Engine, the random split is particularly automated for the user when creating an app that predicts a column in classification or regression. The Engine ensures that it is done correctly in accordance with the best practices recommended in the field of data science and machine learning.
The train-test split method can only be configured during the app-creation step. This keeps the training and test portions the same for all machine learning models trained in the app. This in turn ensures that models are evaluated on the same test portion (a.k.a. hold out or validation portion, used to check how well a machine learning model can perform on new data) of the data so that they can be compared with each other and ranked on a leaderboard.