This article explains what the customer churn prediction template provides in the AI & Analytics Engine.
🎓 For more information about Machine Learning Solution Templates, read What is a template?.
Background
The customer churn prediction template provides a complete machine learning (ML) solution from start to finish, for businesses seeking to reduce customer attrition by predicting their customers' likelihood to churn.
The solution is designed to predict the risk of churn for active customers in advance, according to the desired period configured to suit the business' need. For example, if a business requires 30 days time to mitigate churn, the prediction can be made for currently active customers churning after 30 days.
The template supports two different types of churn use cases, based on two common business models.
🎓 For more information about the types of churn supported within the customer churn template, read What are the two types of churn supported within the customer churn template?.
Similar to all business templates, it is highly accessible to business users without needing any technical expertise in data engineering, ETL, ML pipelines, and etc. Once the models are built, users can examine whether their performance is satisfactory and also understand how they predict.
Predictions generated by the customer churn template:
Using the customer churn template, you simply need to provide a connection to their live database, and obtain periodic predictions sent to chosen destinations on a set desired schedule, in the form of a tabular dataset containing:
- The current active customers (who have not churned)
- Their predicted likelihoods of churn within or after on pre-configured periods
- The features (variables) that were used to make the churn prediction.
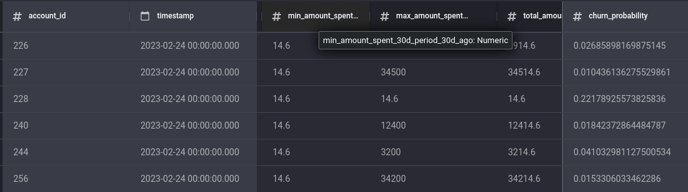 Prediction output from an app built using the transactional option in the Customer Churn Prediction ML Solution Template
Prediction output from an app built using the transactional option in the Customer Churn Prediction ML Solution Template
Analysis of Historical Data
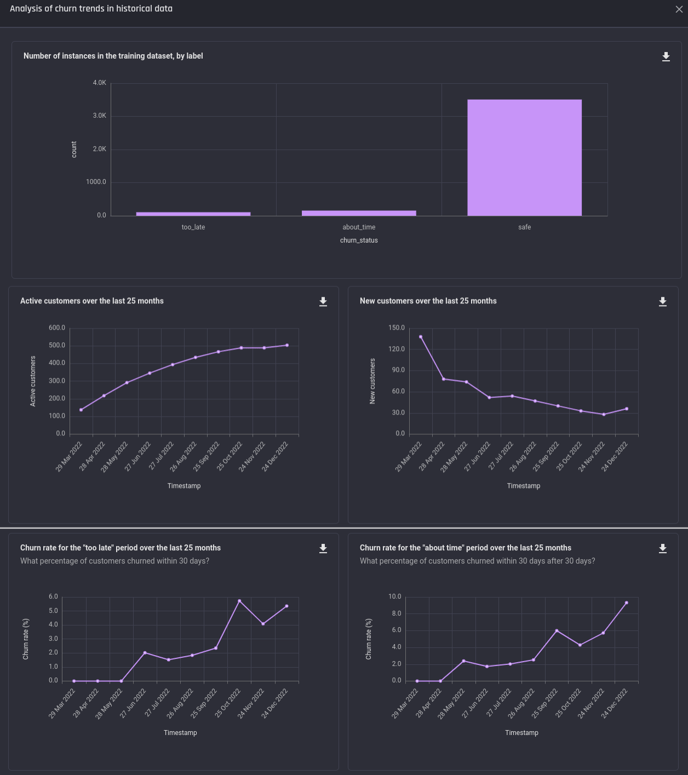
The Engine provides an analysis of the training data once it is prepared. This analysis shows how the churn labels are distributed in the training dataset and the trend of customer activities over the history.
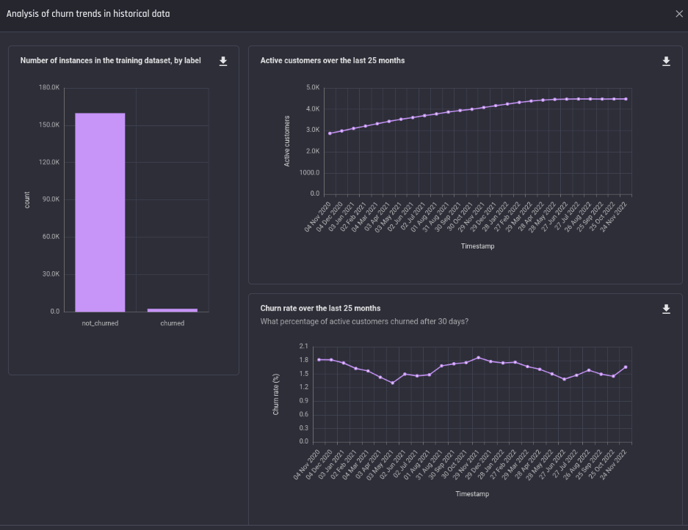 Analysis in the transactional churn use case
Analysis in the transactional churn use case
Model Insights
The Engine also provides all insights for models trained using the churn template, as with any other classification & regression model on the Engine trained with the FlexiBuild Studio option.
You can see how well the model performs on test data consisting of the last 30 days of all data with known outcomes:
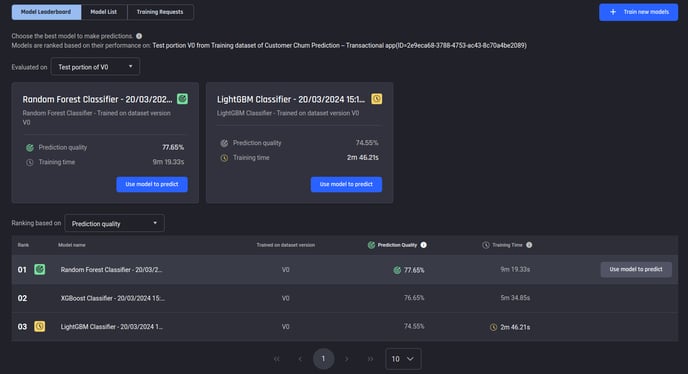 Performance insights: Leaderboard summary
Performance insights: Leaderboard summary
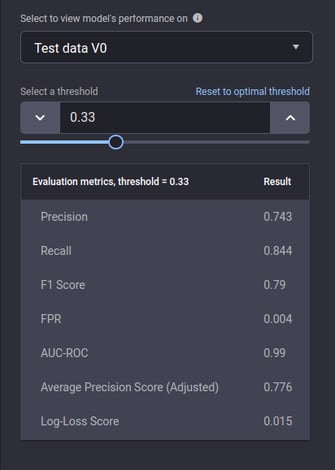 Performance insights: Metrics Performance insights: Metrics |
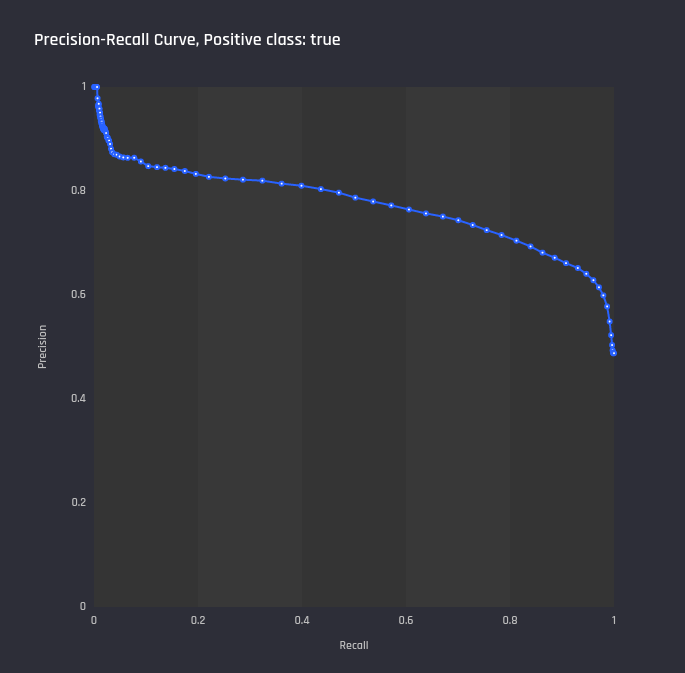 Performance insights: Precision-recall curve Performance insights: Precision-recall curve |
Feature importance provides insight into the most important factors that contribute to churn.
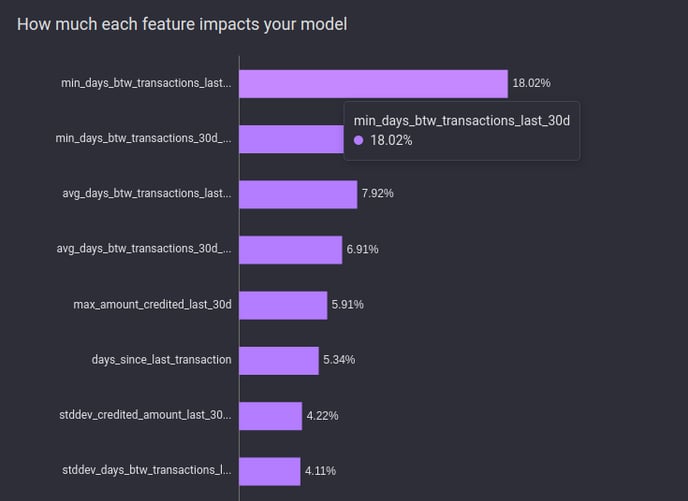 Feature importance values
Feature importance values
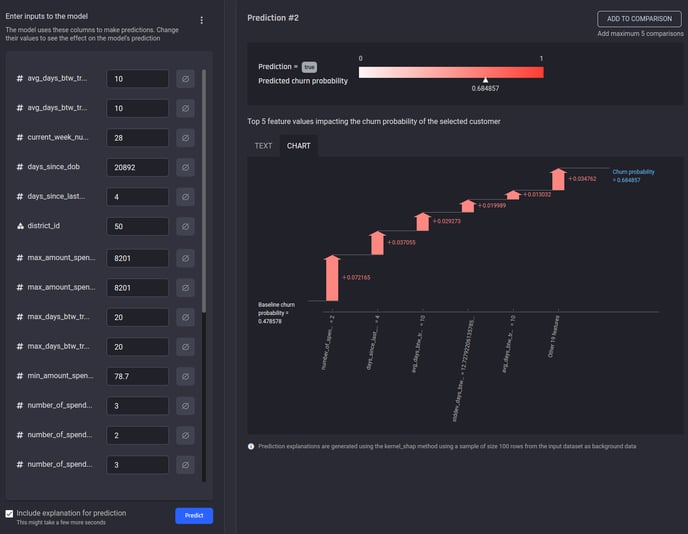
Prediction explanation details how different feature values impact a particular prediction.
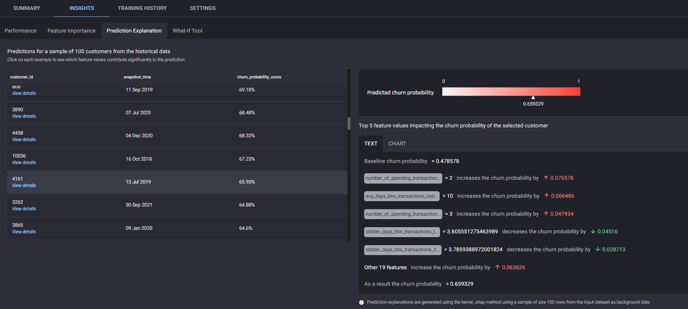 Prediction explanation
Prediction explanation
In prediction explanation, you can click View details to see the details of a particular customer.
Customer details in prediction explanation
The what-if tool provides a way to see how the predictions would change if the values of some contributing factors change.
 What-if tool
What-if tool
Template inputs
The template also provides a way to get a complete ML pipeline by entering only business-specific objectives and domain-knowledge inputs, which does not require any deep technical knowledge of data science or machine learning concepts.
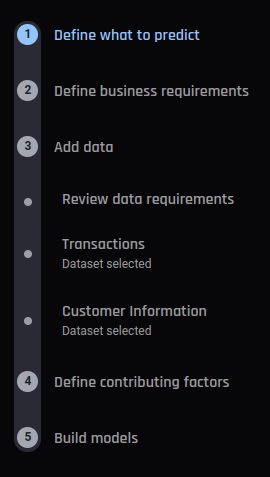
Inputs for transactional churn |
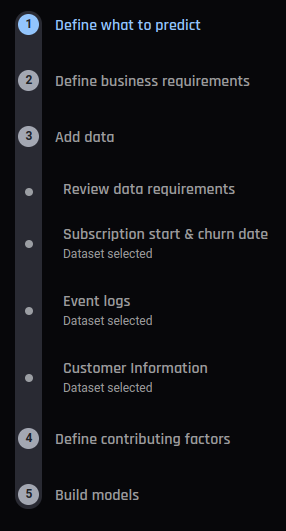
Inputs for subscription churn |
The inputs to the template differ based on the two types of churn supported by it.
As an example, below are the required inputs for the transactional option:
-
Historical transactions datasets
-
Customer information dataset (e.g. age, gender, education level, etc.)
Once the datasets have been defined, the template requires additional configuration details:
-
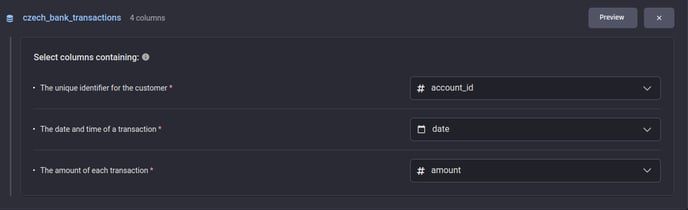
Identification of specific columns: Which column stores customers' unique identifiers (ID), which column stores the transaction timestamp, and which column stores the transaction amount.
-
Definition of business requirements: How churn is assessed in your business based on activity threshold (e.g. 30-day period with < 100 dollars in total monetary value)
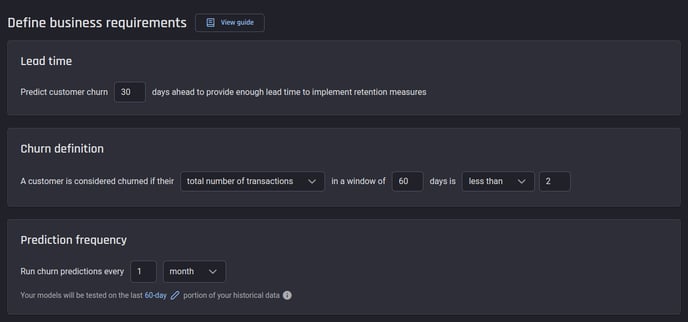
-
Domain-knowledge input: Where signals that foretell impending churn can potentially be found, in other words the parameters of the time windows relative to the prediction date.
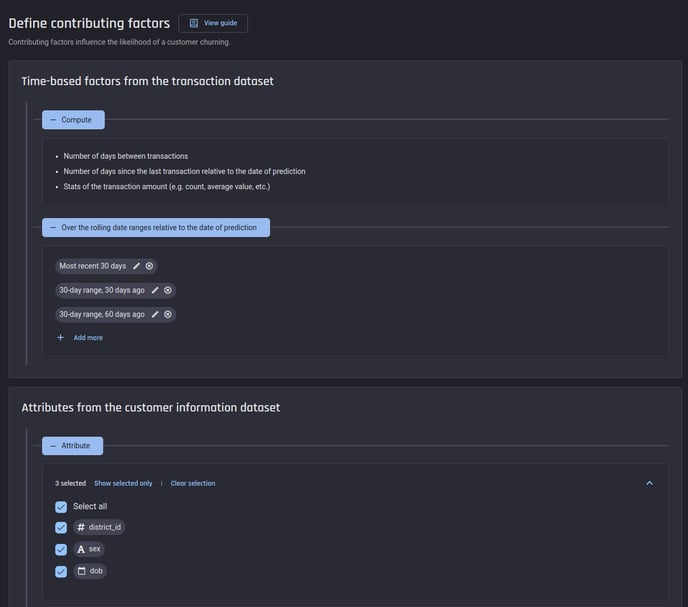
-
Choice of model training: Either let the Engine automatically identify the top models and train them straightaway, or pick them manually.
No other input or configuration is needed. The template automatically does the heavy lifting by building the right data science & machine learning solution based on the user’s business objectives – without requiring the need for any technical concepts.
Automation provided by the template
The churn template completely automates the process of aggregating and joining the various input datasets in a suitable manner, by:
- Providing full automation of feature engineering and data wrangling process.
- It then immediately proceeds pick the right ML problem type (classification) and the target column
- It then creates and processes the necessary feature sets, and trains the models according to the selection in the template
- At the end, it will allow the user to run the entire pipeline in prediction mode using the chosen trained model, and automatically obtain periodic predictions. One-time predictions can also be triggered with a simple point-and-click UI interface
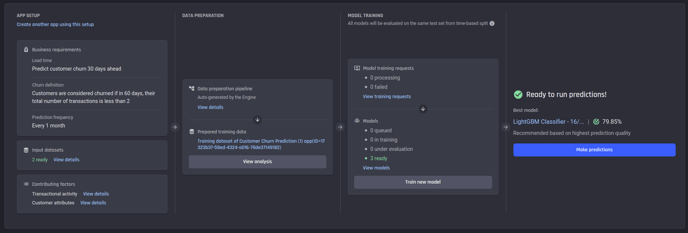 App summary page
App summary page
Once the data and the business-problem definitions are provided, the Engine automatically processes everything and provides a trained model to predict churn.