This article explains how the models are evaluated in the customer churn prediction template.
Model evaluation is an essential step in the process of building machine learning solutions. Through evaluation, the most suitable model can be selected, and its real-world performance can be measured.
How AI & Analytics Engine evaluates models in a Machine Learning Solution Template app
When a user builds an app using a Machine Learning Solution Template, the AI & Analytics Engine automatically selects the optimal model-evaluation method based on the original machine-learning problem of that template. For example:
-
For the transactional customer churn prediction template, the Engine will evaluate using metrics for binary classification problems.
-
For the customer lifetime value prediction template, the Engine will evaluate using metrics for regression problems.
Characteristics of the ML Solution Template app evaluation process
The evaluation process of ML Solution Template apps has similar characteristics to FlexiBuild Studio apps, along with some automatic options.
1. The Engine will automatically choose the appropriate way to split the data into training and test sets based on the template's business problem. For example, with time-dependent problems like customer churn or customer lifetime value prediction, the Engine will hold out a time period at the end of the dataset for testing (time-based split). This test set duration is automatically set to match the prediction frequency. By default, the prediction frequency is 1 month, so the test set covers the last 30 days of data. However, users have the flexibility to adjust this number according to their specific business requirements.
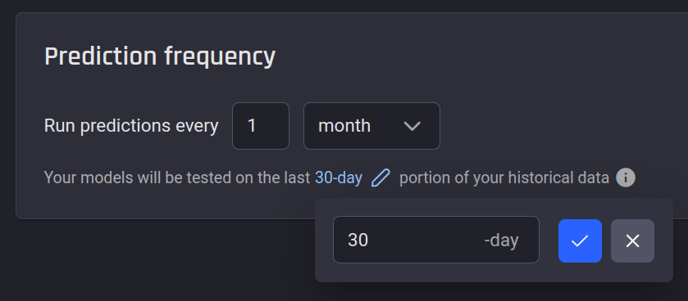 Customize the time-based split test portion
Customize the time-based split test portion
2. After training, the model will be evaluated using metrics appropriate for the template's machine learning problem. At the same time, the Engine also automatically selects a representative metric that best reflects the prediction quality, allowing users to quickly assess the model.
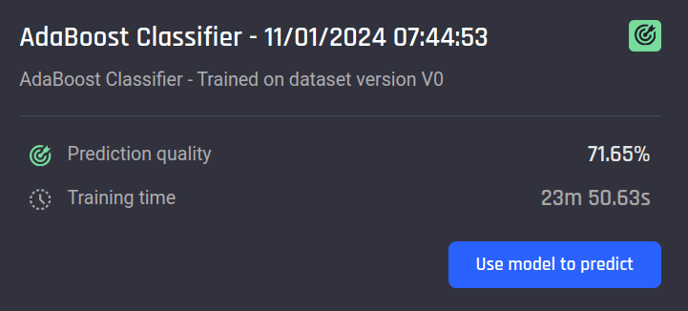 Model performance card in the model leaderboard
Model performance card in the model leaderboard
3. Common metrics and illustrative charts are provided in the model performance report, similar to apps built using FlexiBuild Studio.
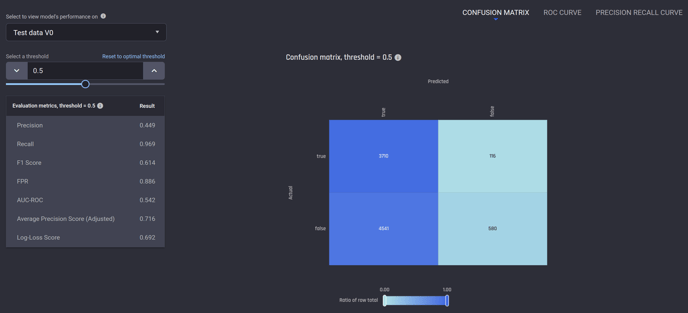 Evaluation report for a transactional customer churn prediction app (binary classification)
Evaluation report for a transactional customer churn prediction app (binary classification)
🎓To learn more details about the model evaluation process, read Evaluating model performance in the Engine