The primary objective of creating an app on the AI & Analytics Engine is to generate predictions that can support future business-decisions based on available data.
The Engine offers two modes of prediction:
-
One-time prediction: this is the basic mode of prediction. Users can obtain the prediction results by providing the required data for prediction, either by importing new datasets, or using existing datasets on the platform. This mode is usually used when predictions are not required on an ongoing business.
For example, you could be conducting research, and building a model to predict whether a specific drug will be effective to treat a condition, based on various features of the patient, condition and the drug. You train a model and then run the prediction. Once you have the results, you could move forward with your study, and have no need of running the predictions again.
-
Scheduled periodic prediction: this mode is suitable for production environments. It automatically generates predictions at regular intervals based on user-defined schedule. The data is refreshed from predefined sources before each prediction. Thus, the user can access the latest results without manually making predictions as in the one-time mode.
For example, you could be a retail company interested in predicting the propensity of clients to take up on a specific offer, as part of an effort to increase sales or the customer lifetime value. Assuming that you trained a model based on historical take up of marketing offers, based on the offers and clients features. You could predict on a monthly basis, for all the new customers added every month and the existing customers who have yet to accept the offer, what is their likelihood of accepting it. The main advantage here is that you always use your updated customers list for the predictions in every month.
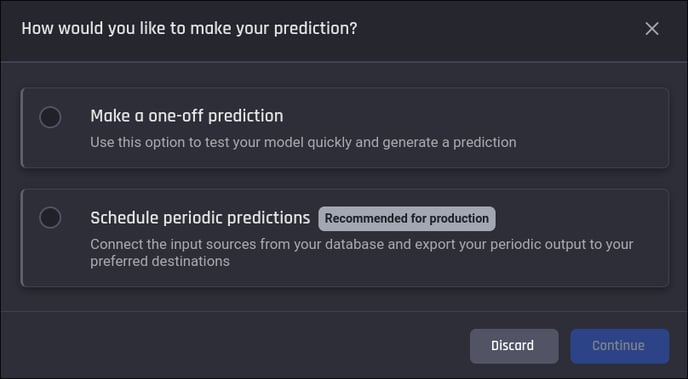 Dialog for choosing prediction mode
Dialog for choosing prediction mode
In both modes, the data schema should match the one used for training the model. Users can select the most suitable mode of prediction, according to their needs. For more details on how to perform, and how the two modes of prediction operate in practice, refer to the following use-cases: