





Getting Started with AI/ML
Machine Learning Classification Algorithm: Decision Trees
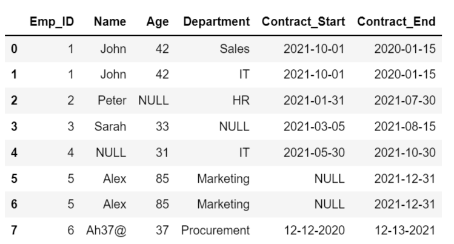
In this blog, we implement the decision tree classifier. What takes hours in Python, it only takes a few minutes on the AI & Analytics Engine...