
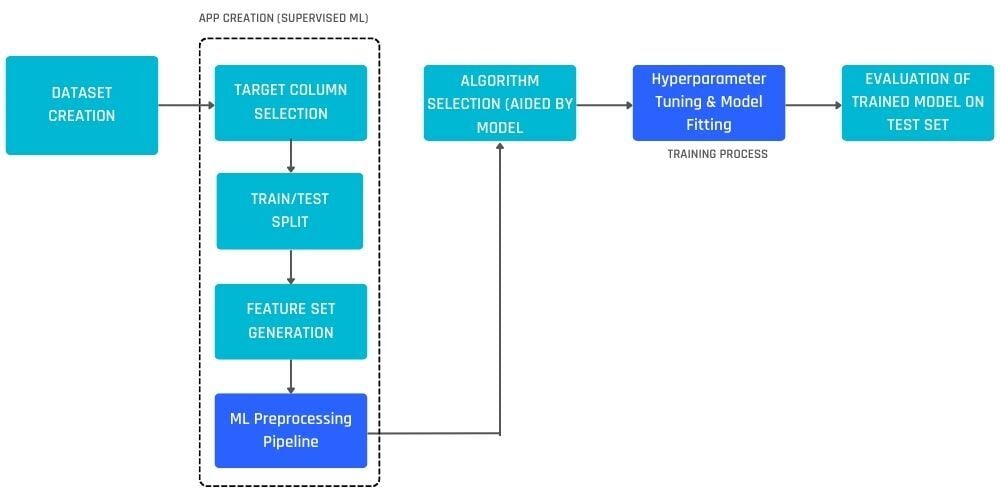
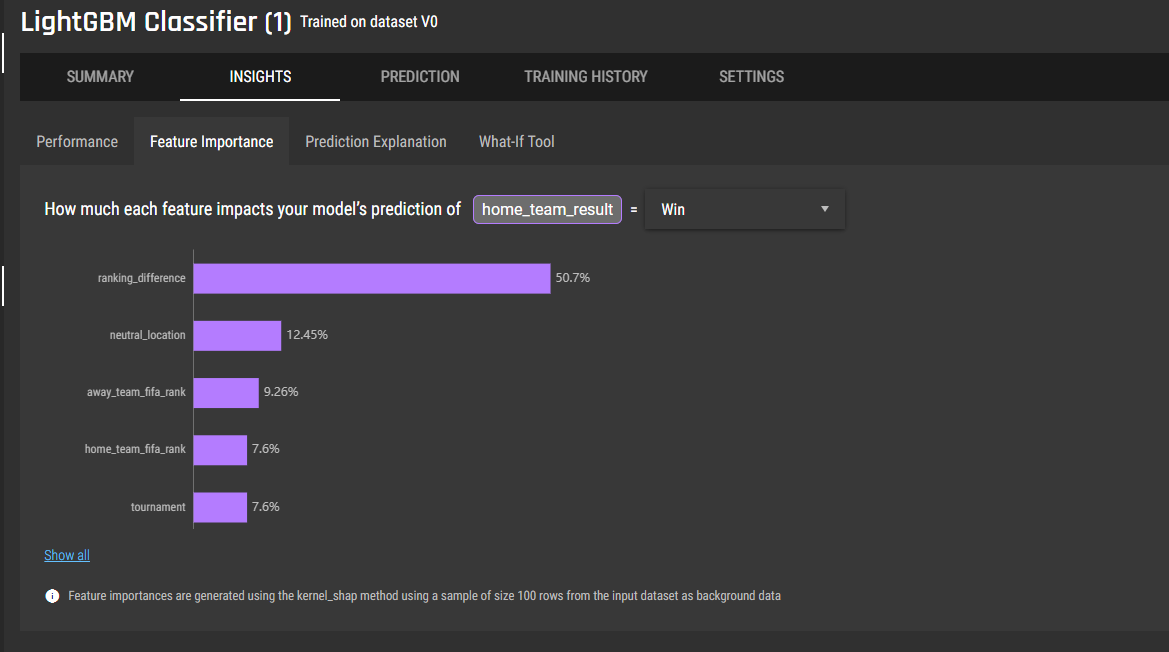
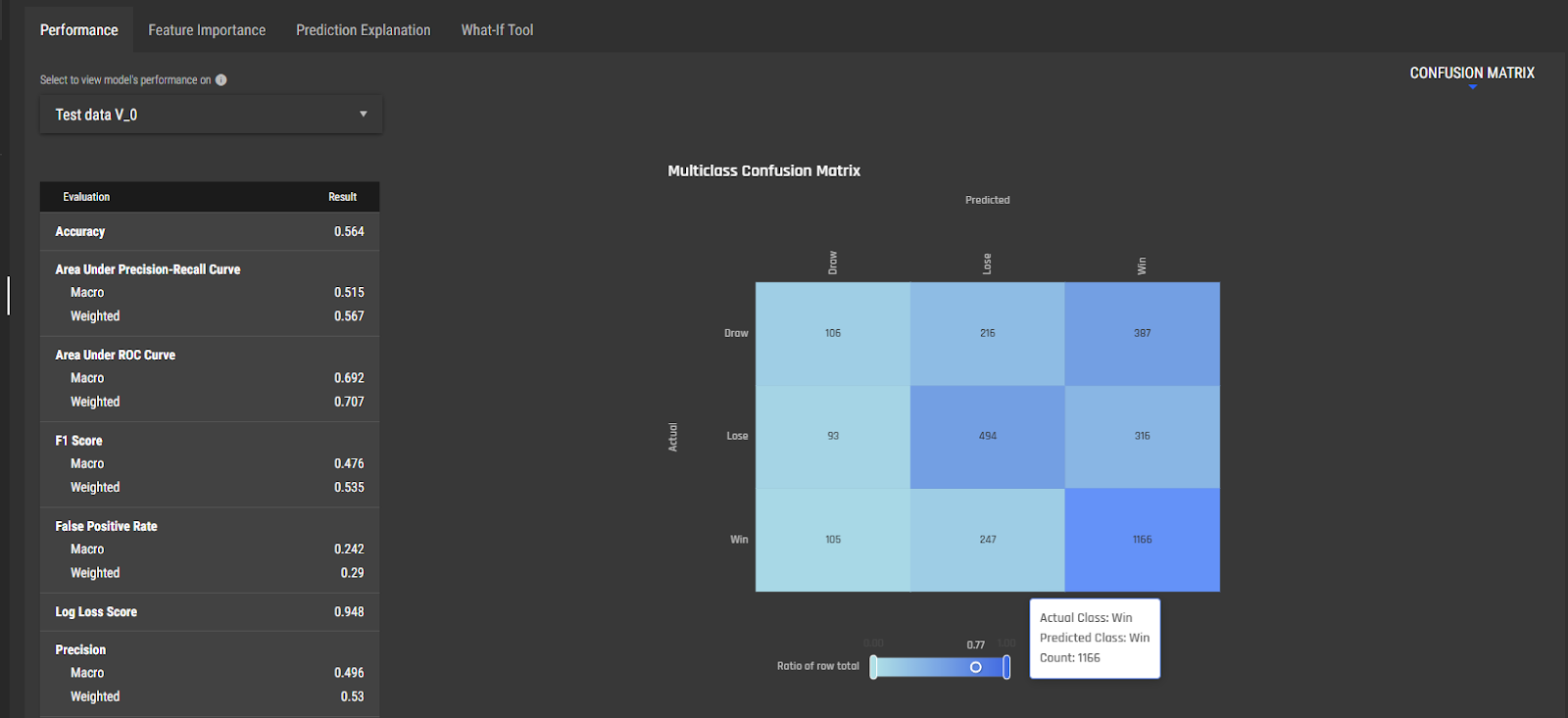
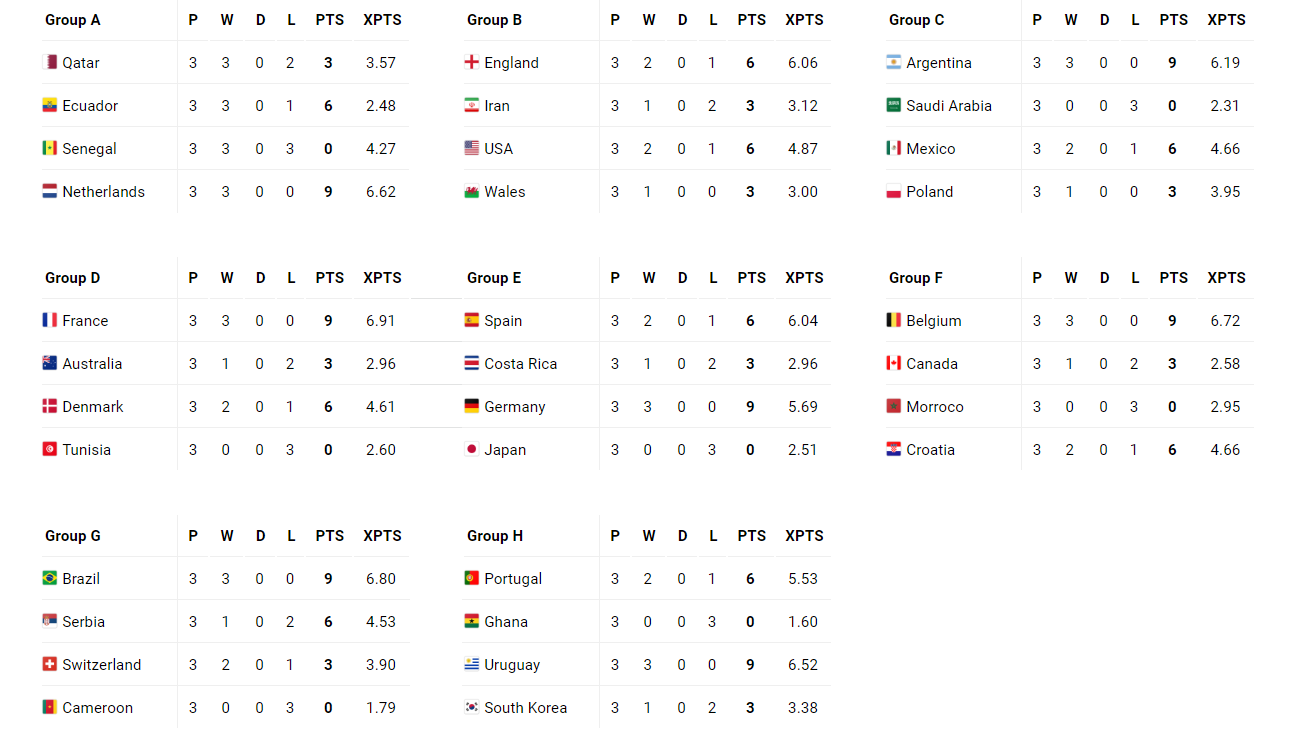
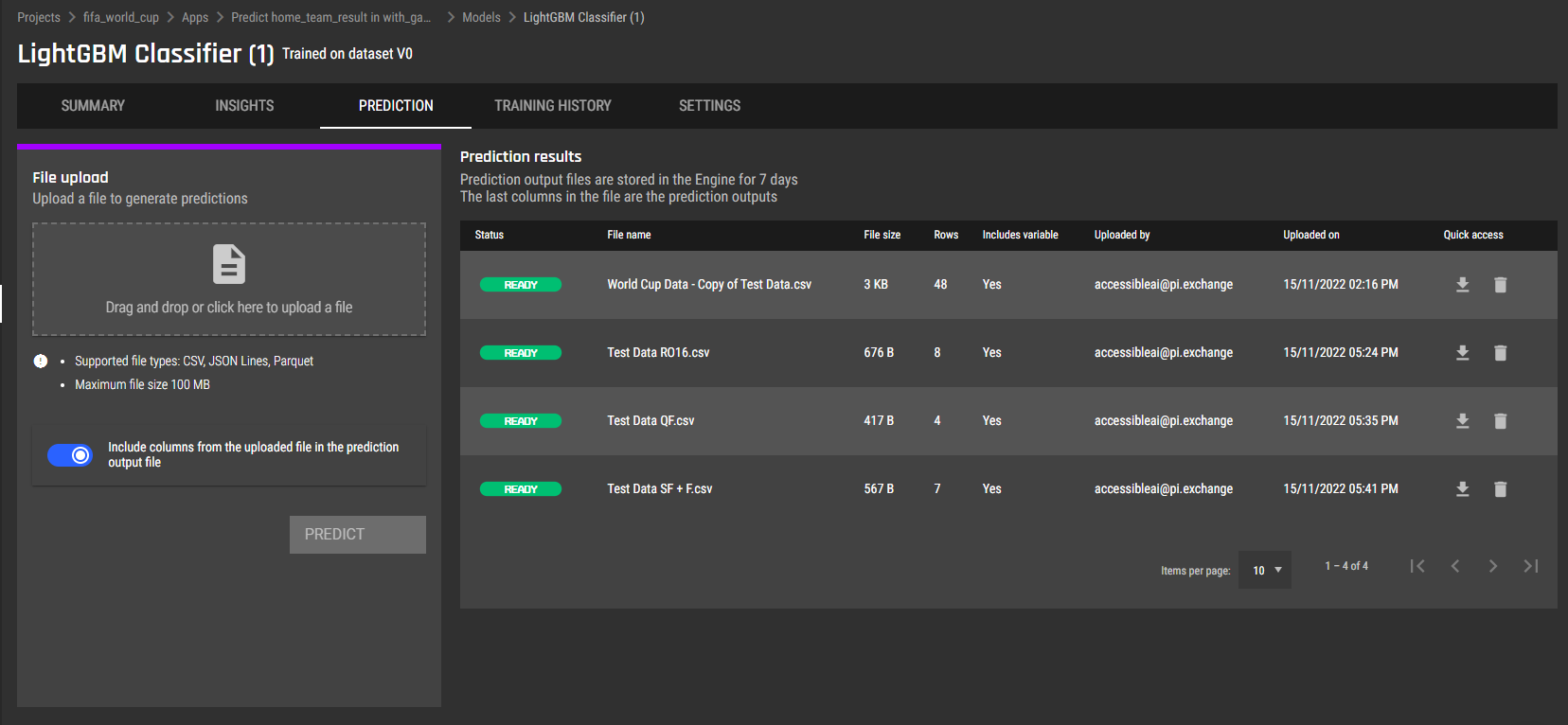
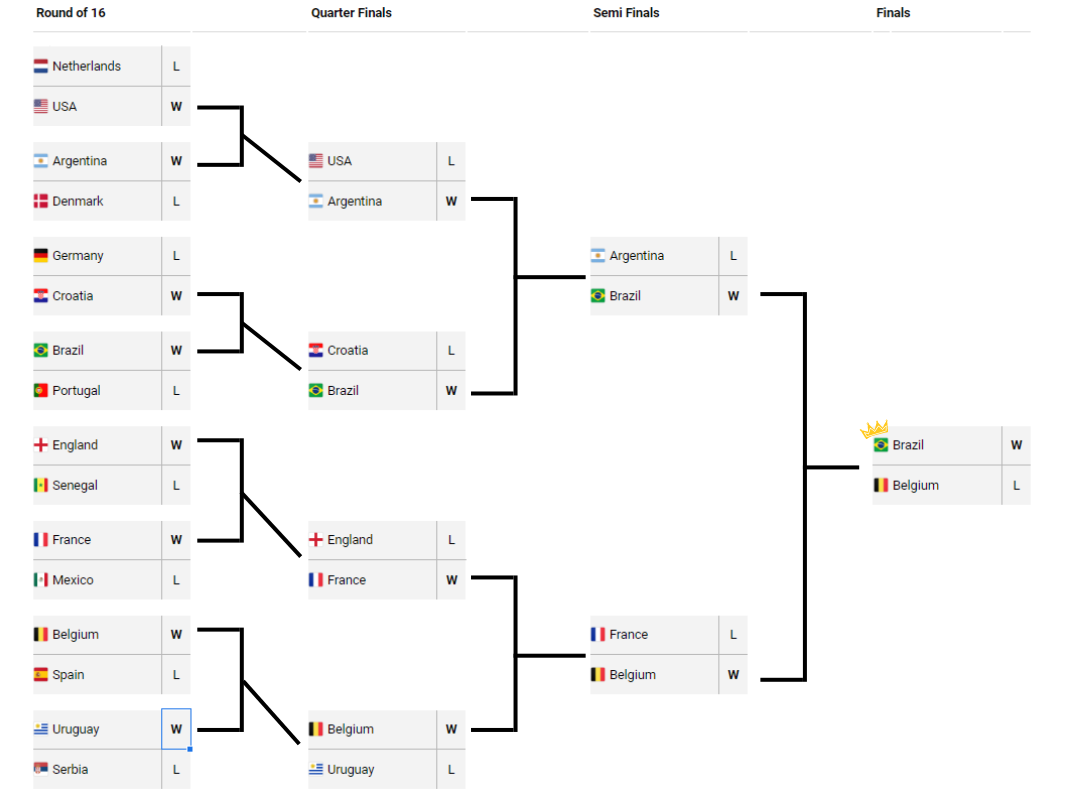

Predictive analytics
How Predictive Analytics is Driving Evolution in Insurance
The adoption of predictive analytics in the insurance industry is spearheading rapid evolution, leading to improved efficiency, and streamlined...