
















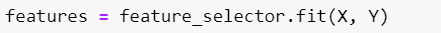



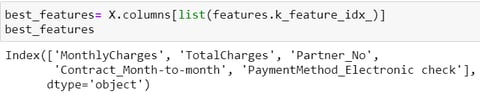

Model Insights
Feature Importance in Machine Learning - The AI & Analytics Engine
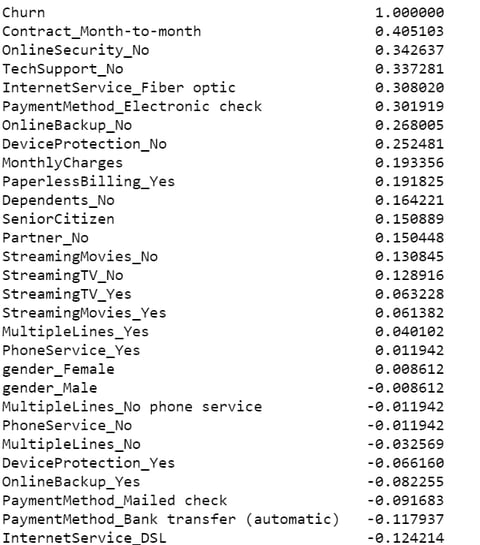
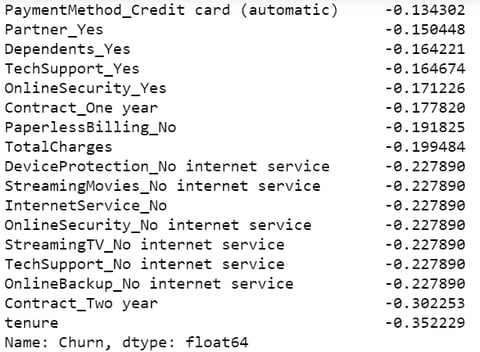
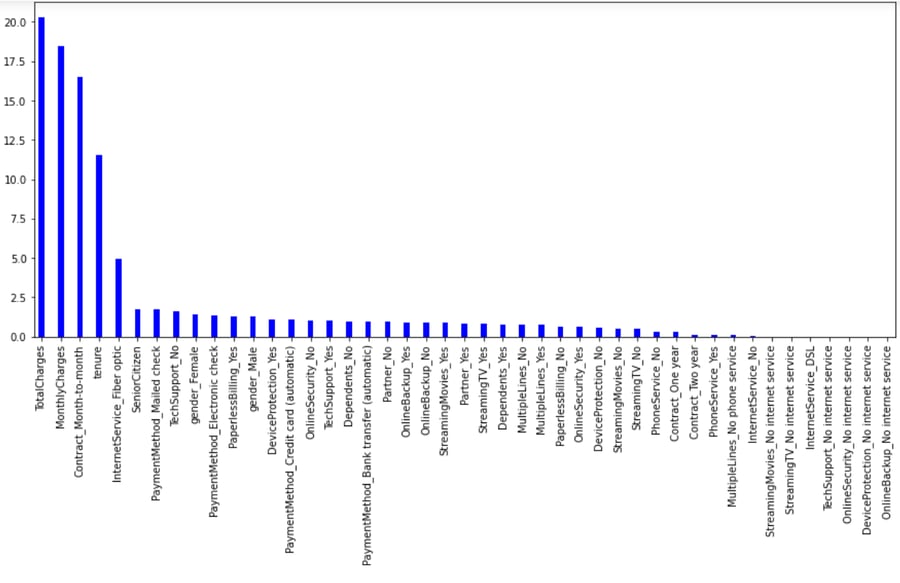
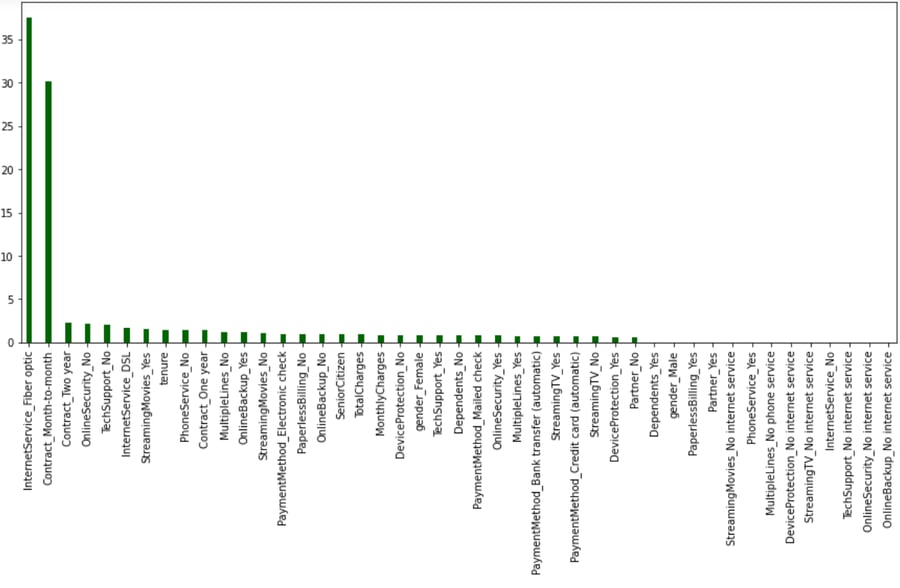
Feature importance in machine learning is a method of calculating a score that displays the relative impact of each feature on the generated...