

No code data science
Unsupervised Machine Learning: K-Means Clustering
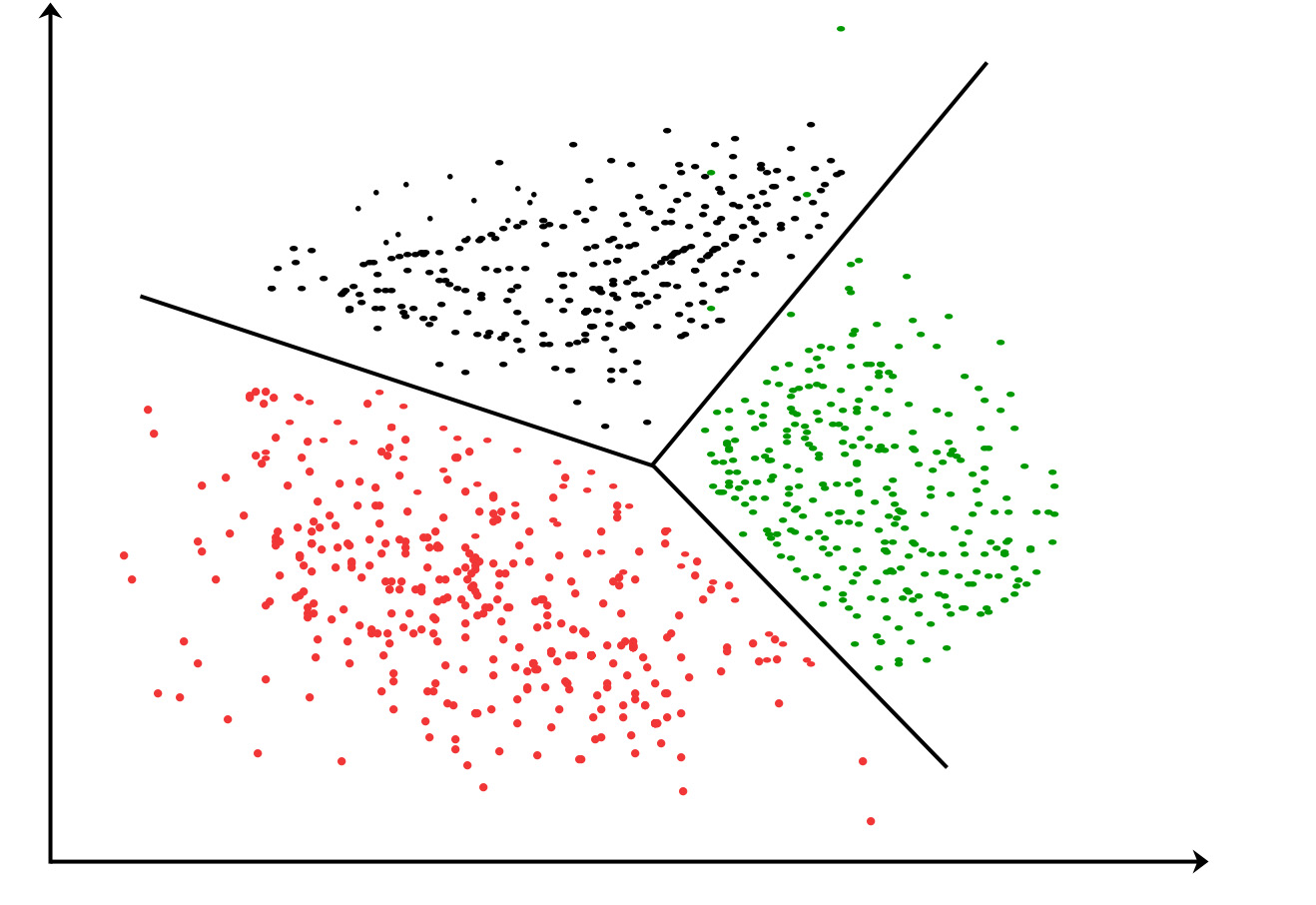
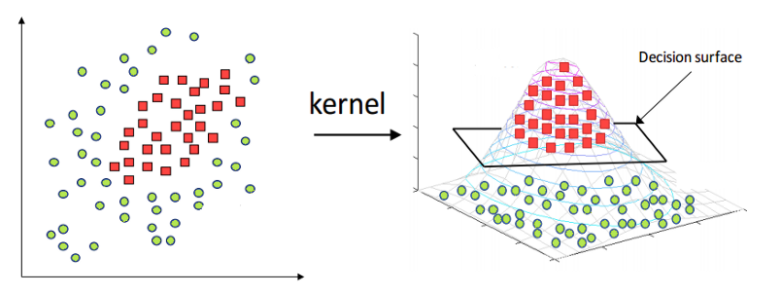
Having discussed in detail supervised machine learning algorithms, we focus on an unsupervised machine learning algorithms: K-Means clustering.