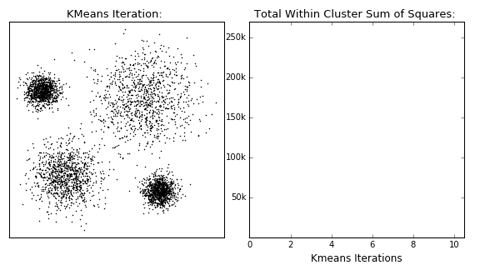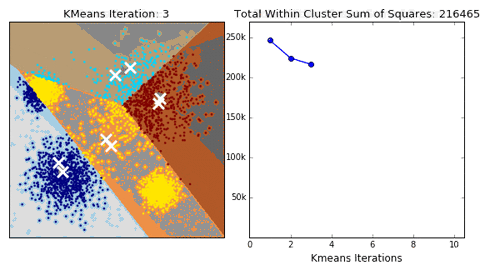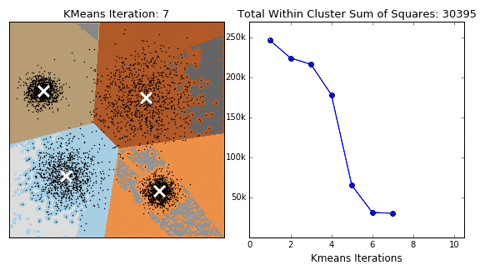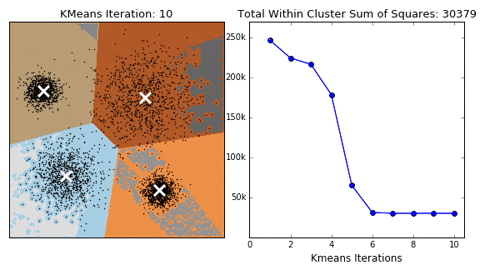

Classification
Support Vector Classifier Simply Explained [With Code]
Let's take a deep dive & try to understand Support Vector Classifier, a popular supervised machine learning classification algorithm with the help of...