
.png?width=800&name=Add%20a%20subheading%20(1).png)
.png?width=800&name=Blog%20Images%20(1).png)
.gif?width=800&name=ezgif.com-gif-maker%20(3).gif)

.png?width=800&name=Blog%20Images%20(45).png)

ML for small businesses
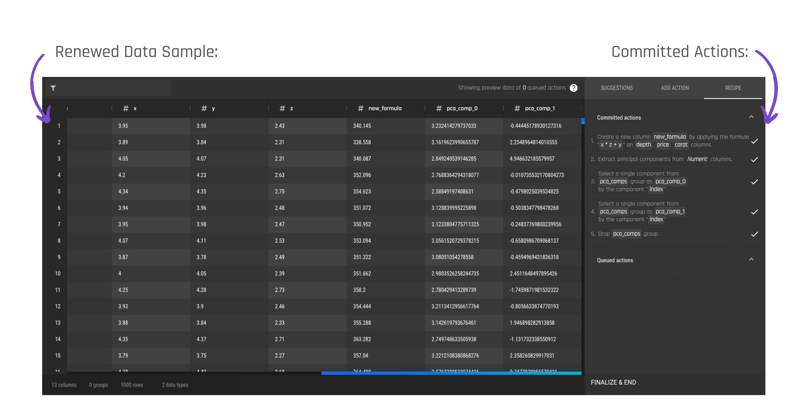
AI & Analytics Engine Tutorial 2/4: Data Preparation
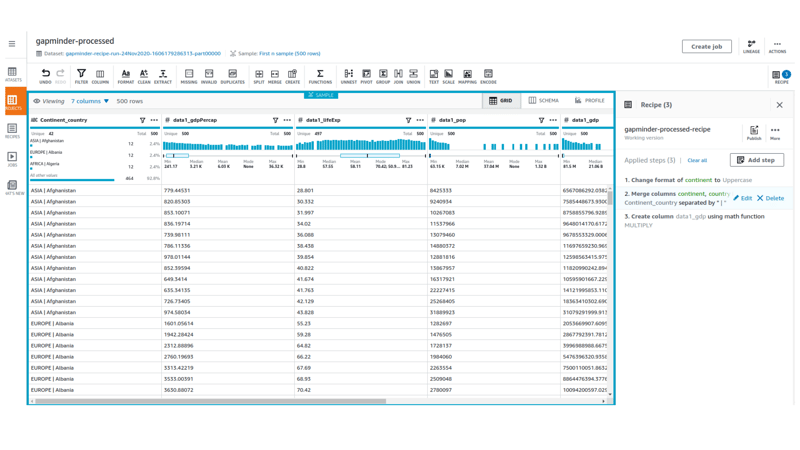
Here, you will learn how to leverage the AI & Analytics Engine for data preparation to be consumed by an ML model in a streamlined and repeatable way.