
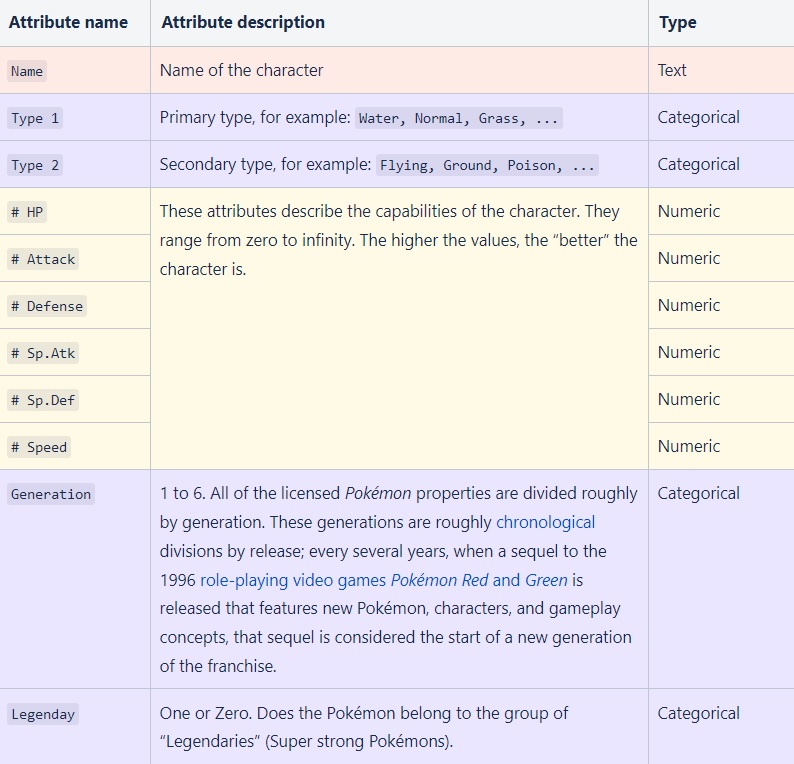
 Fig 1 - Sample of the initial Pokémon dataset analysis
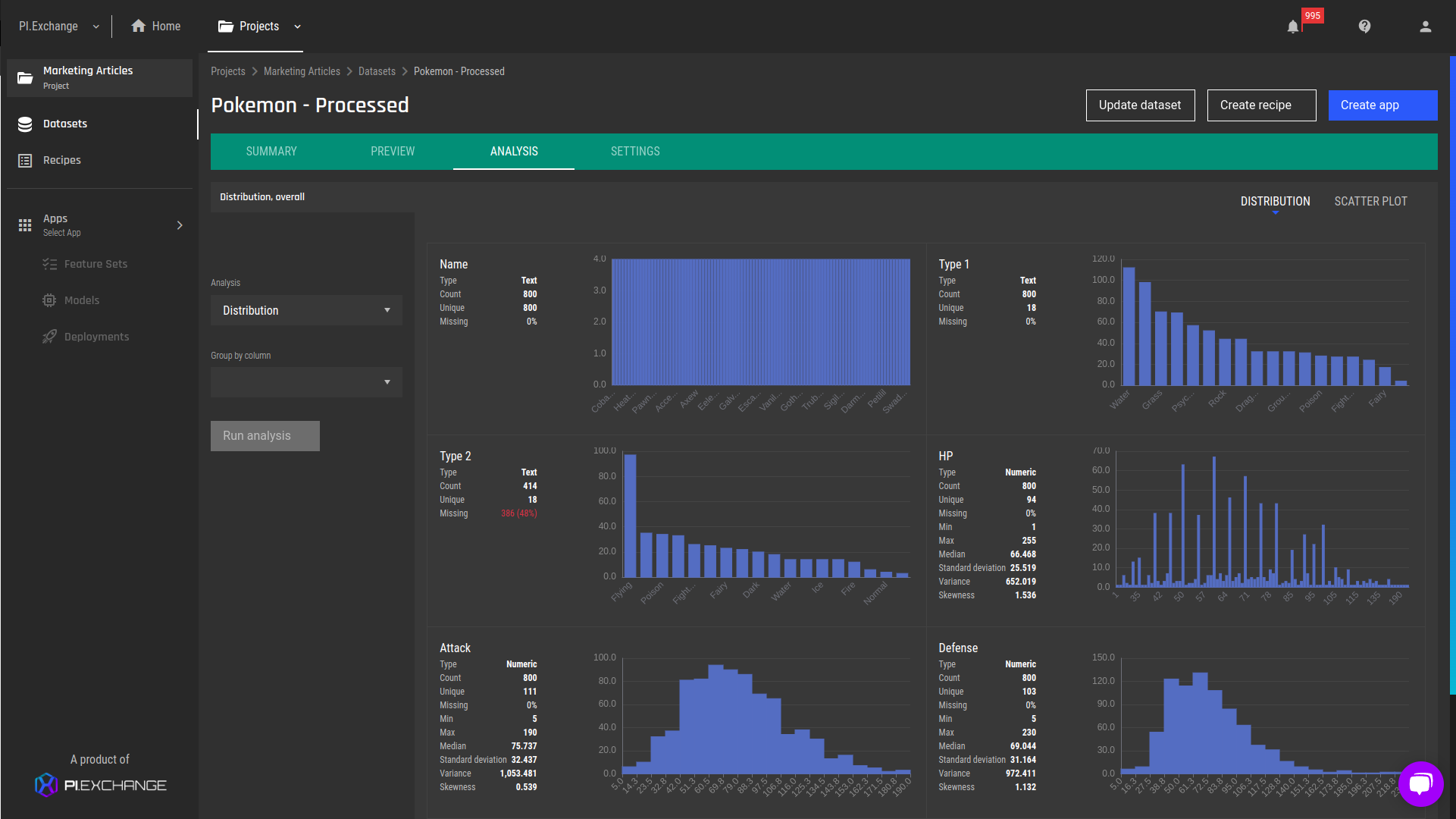
Fig 1 - Sample of the initial Pokémon dataset analysis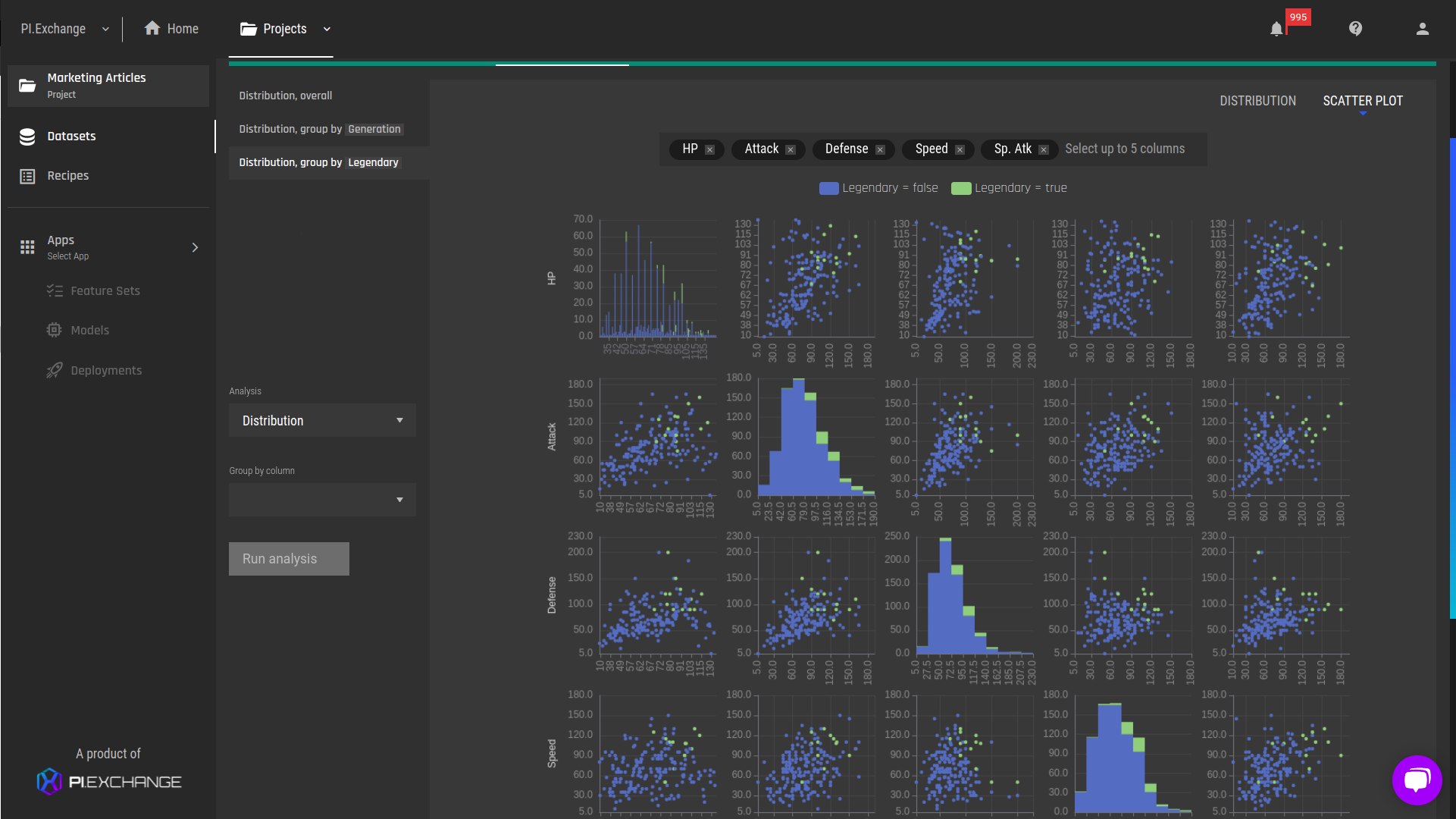 Fig 2 - Features analysis grouped by the "generation" feature
Fig 2 - Features analysis grouped by the "generation" feature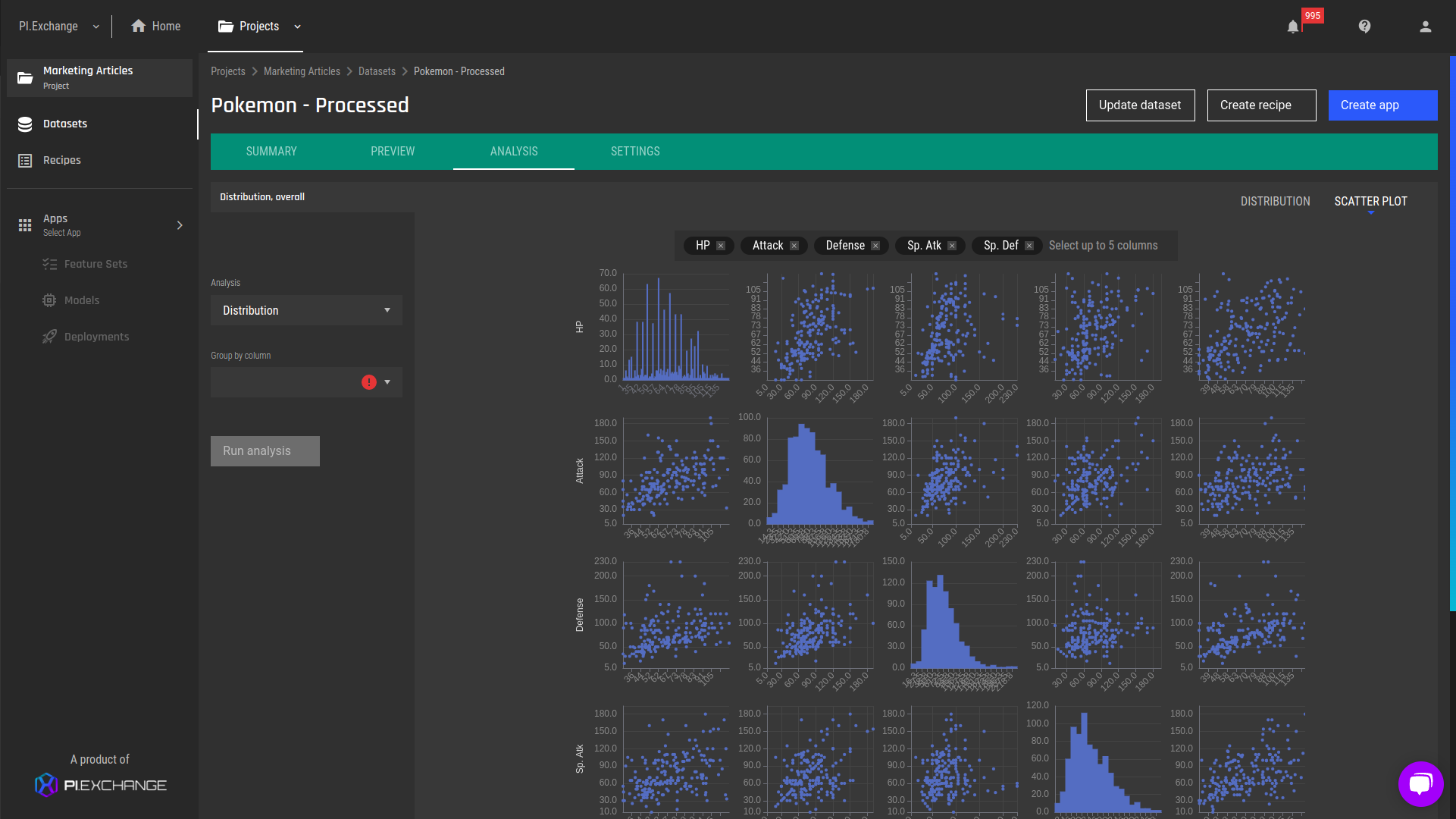 Fig 3 - Pair plot (zoomed in) - physical attributes
Fig 3 - Pair plot (zoomed in) - physical attributes.png?width=1921&name=tmp%20(1).png) Fig 4 - Pair plot (zoomed in) - physical attributes grouped by the "Legendary" feature. The green dots represent the feature values for legendary Pokémon, and we can easily see that their physical attribute values are much higher compared to the non-legendary Pokémon.
Fig 4 - Pair plot (zoomed in) - physical attributes grouped by the "Legendary" feature. The green dots represent the feature values for legendary Pokémon, and we can easily see that their physical attribute values are much higher compared to the non-legendary Pokémon.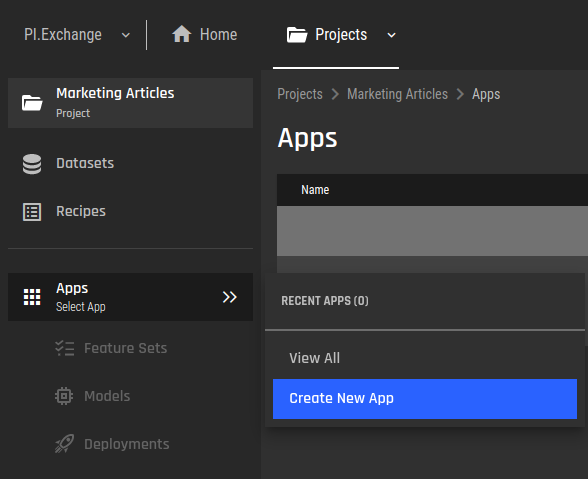 Fig 5 - New app creation
Fig 5 - New app creation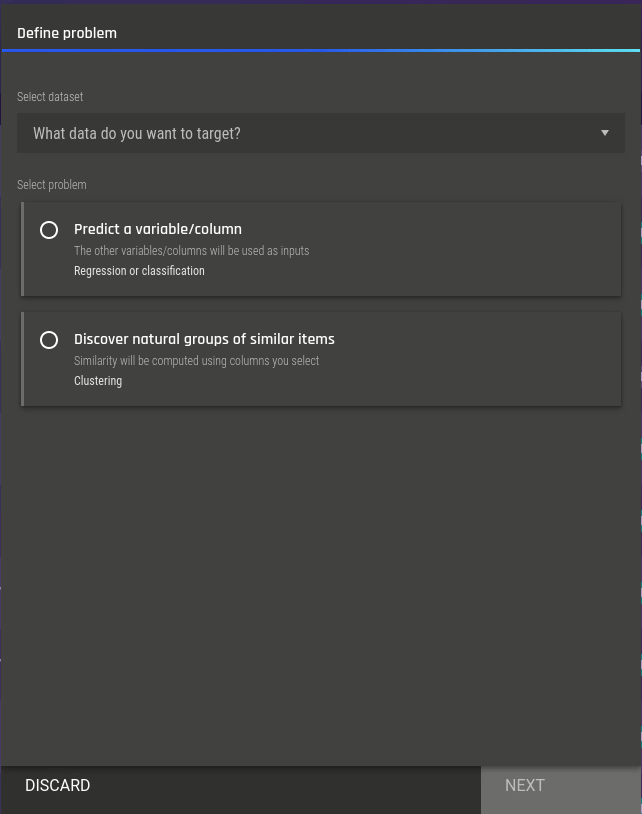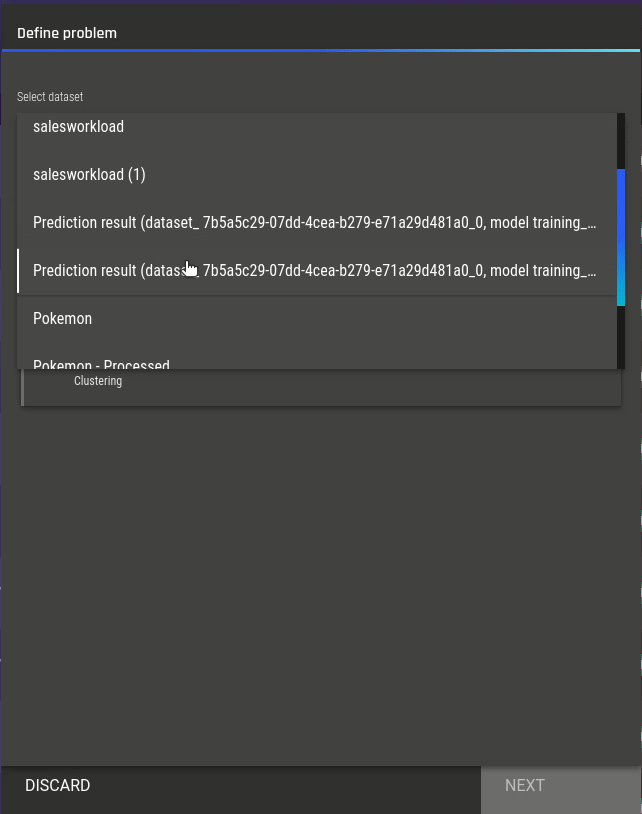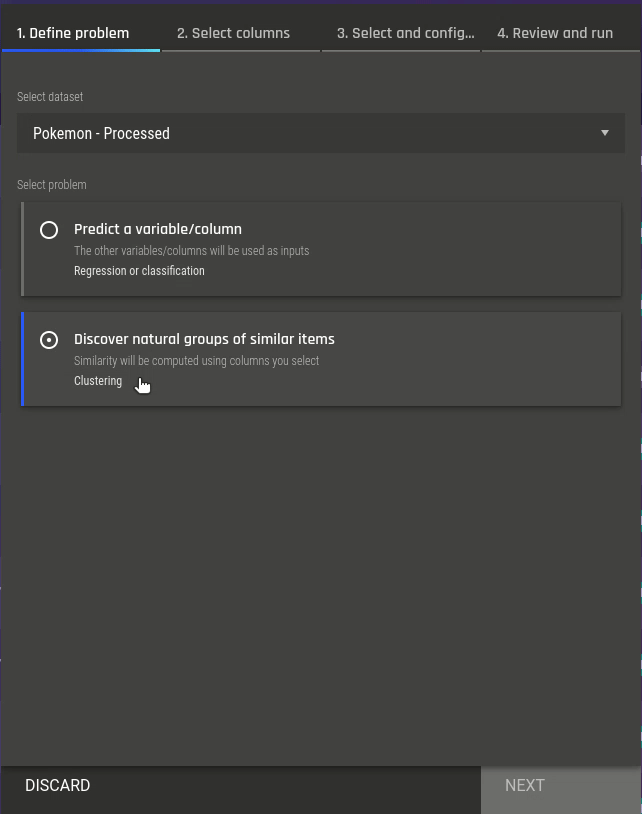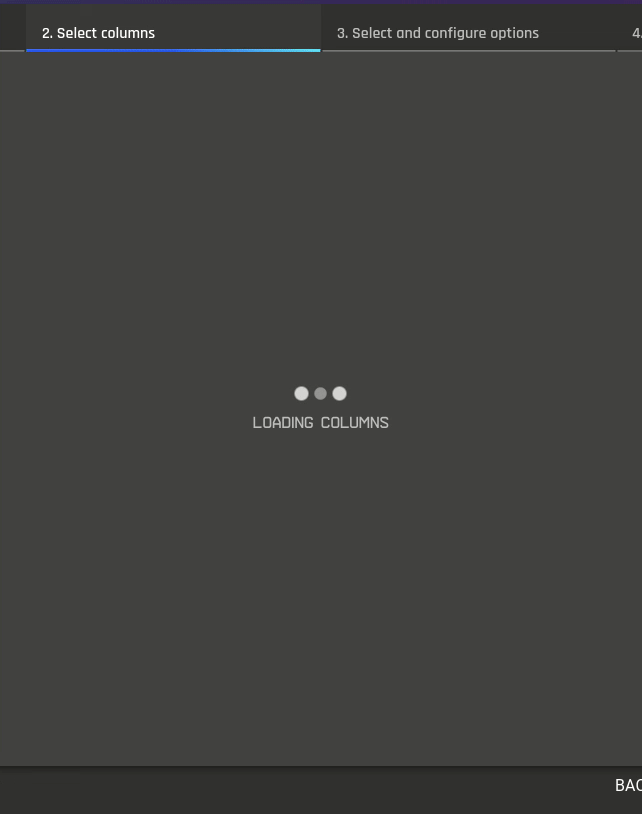 Fig 6 - Selecting the clustering app
Fig 6 - Selecting the clustering app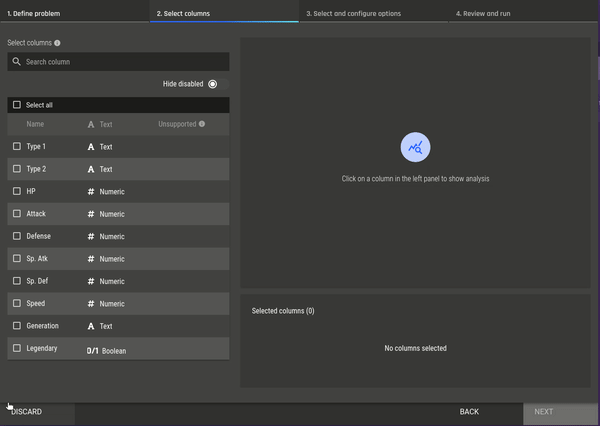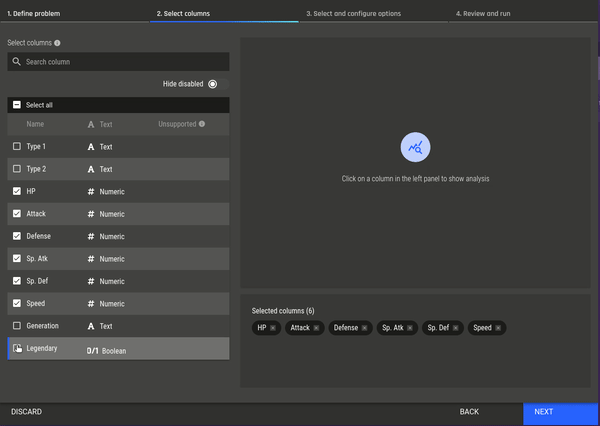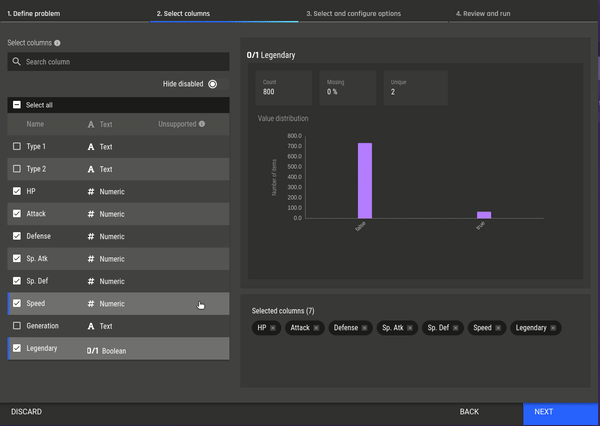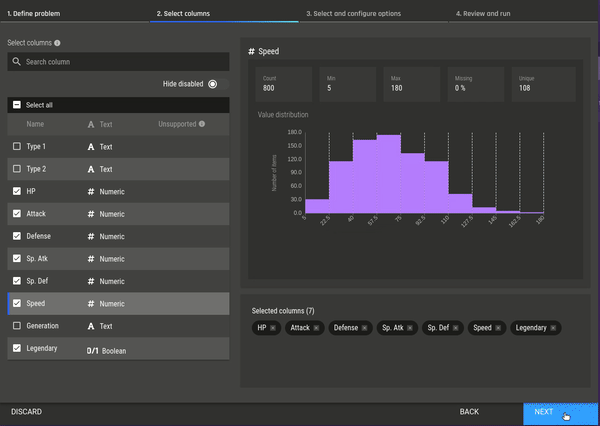 Fig 7 - Selecting features for clustering
Fig 7 - Selecting features for clustering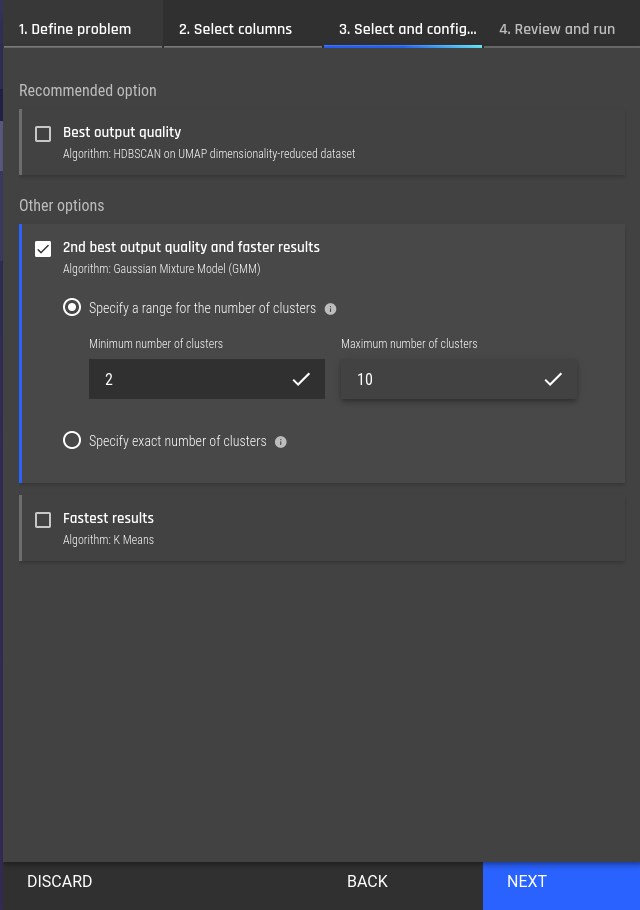 Fig 8 - Selecting a clustering algorithm
Fig 8 - Selecting a clustering algorithm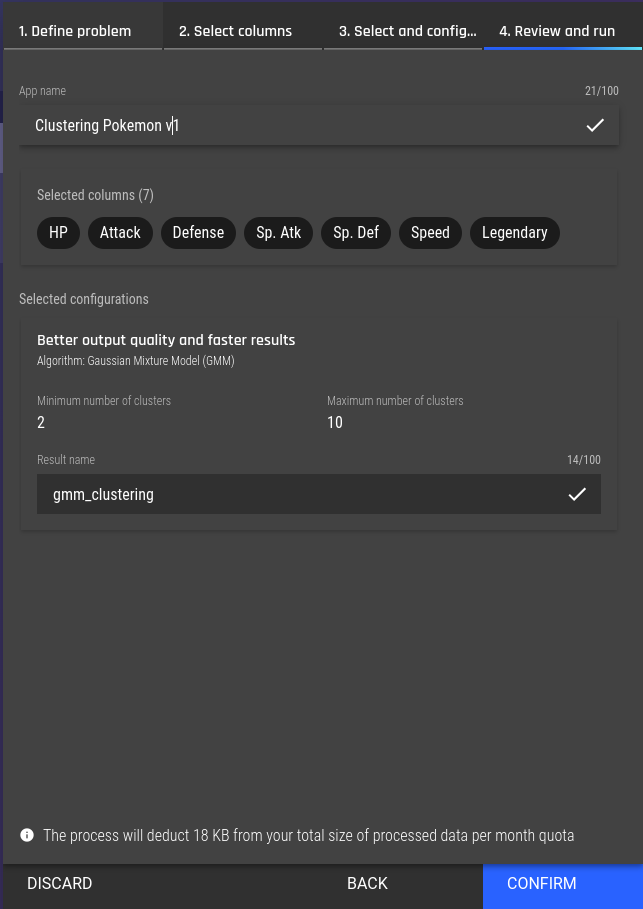 Fig 9 - Review the clustering configuration
Fig 9 - Review the clustering configuration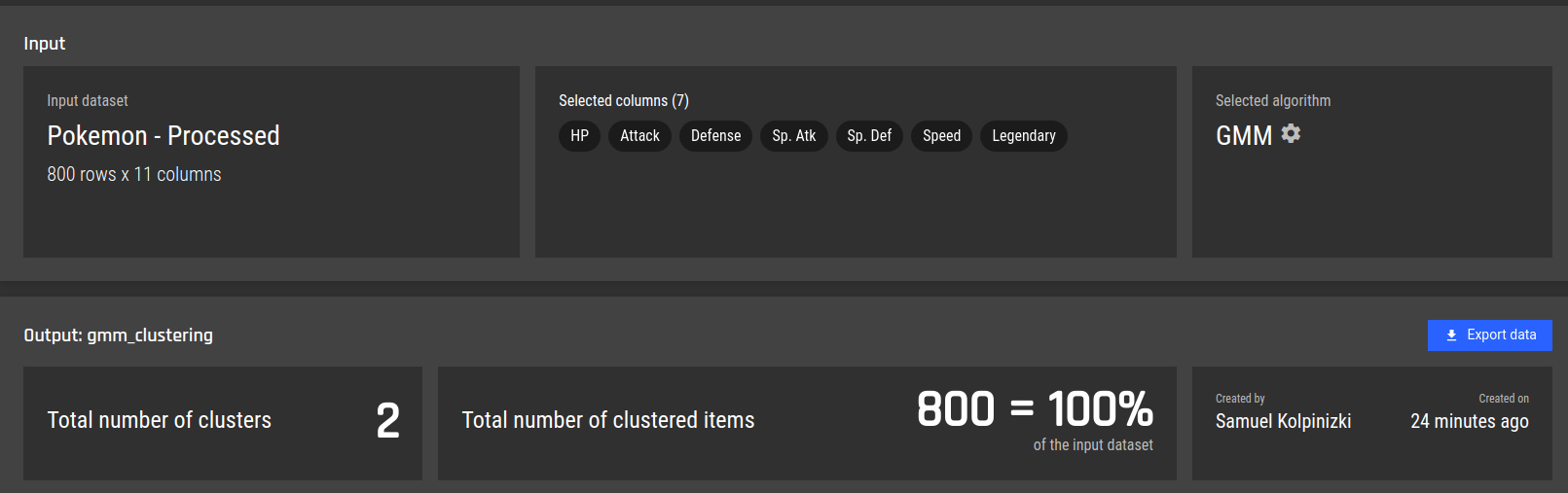
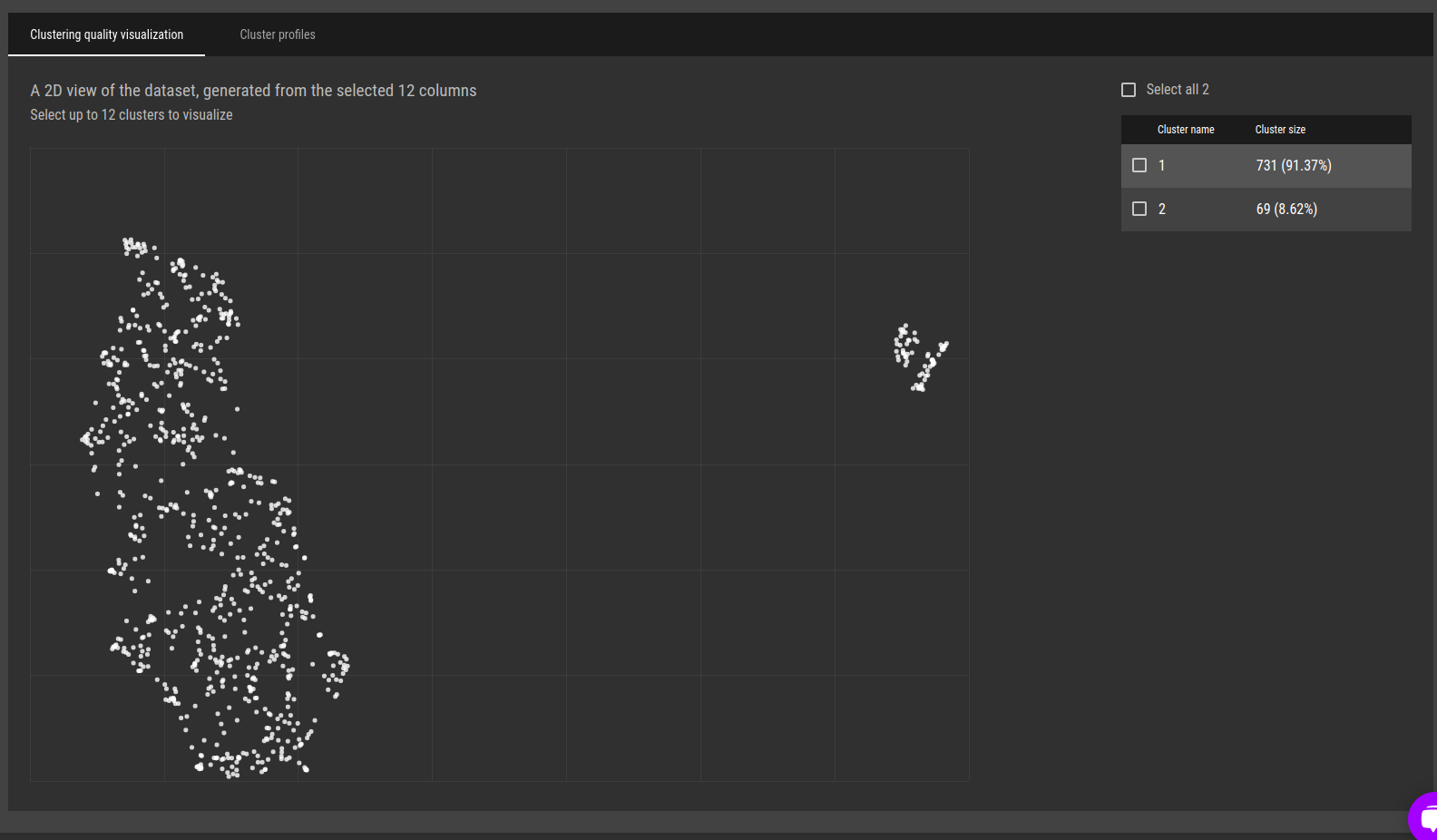
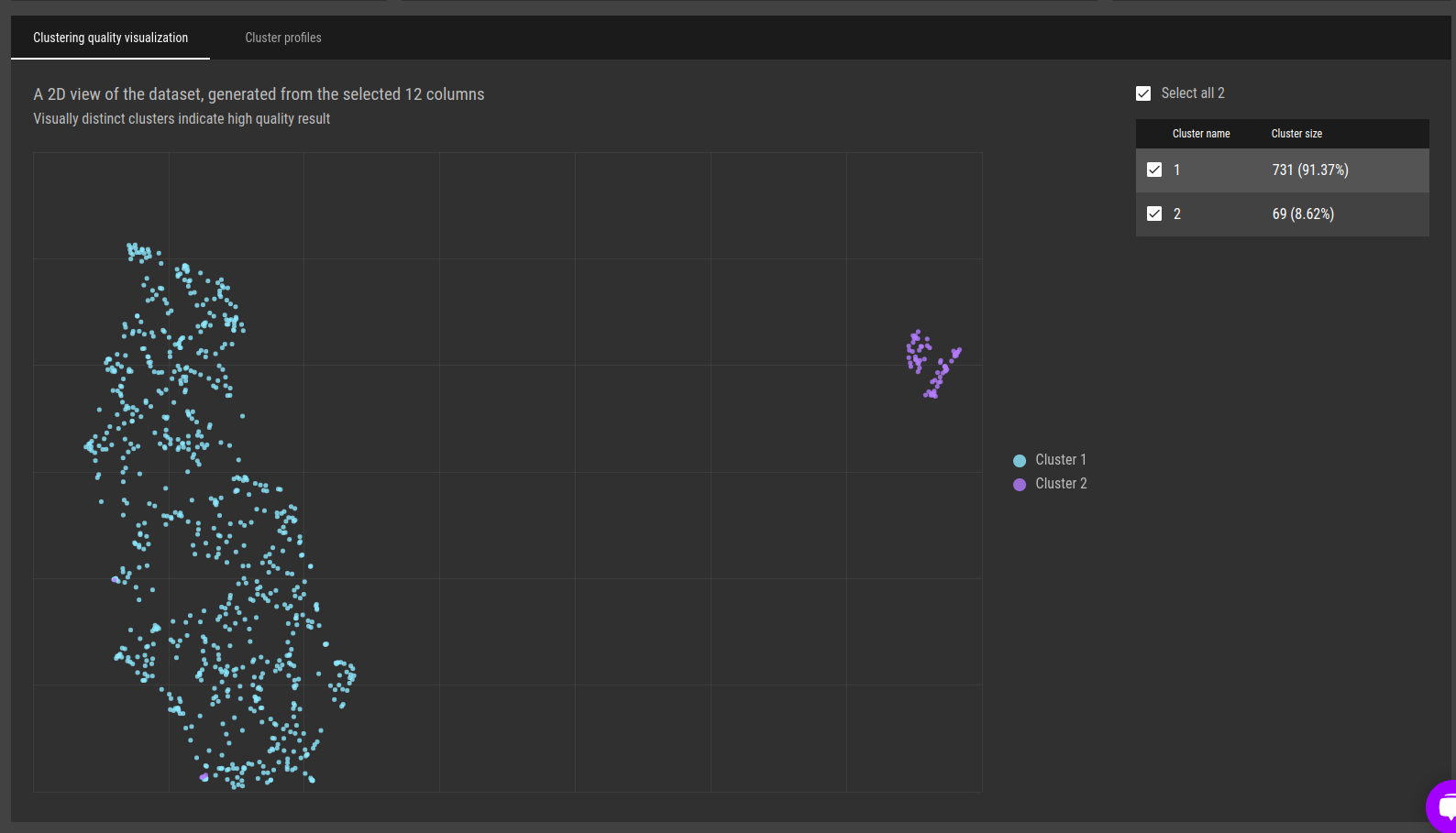
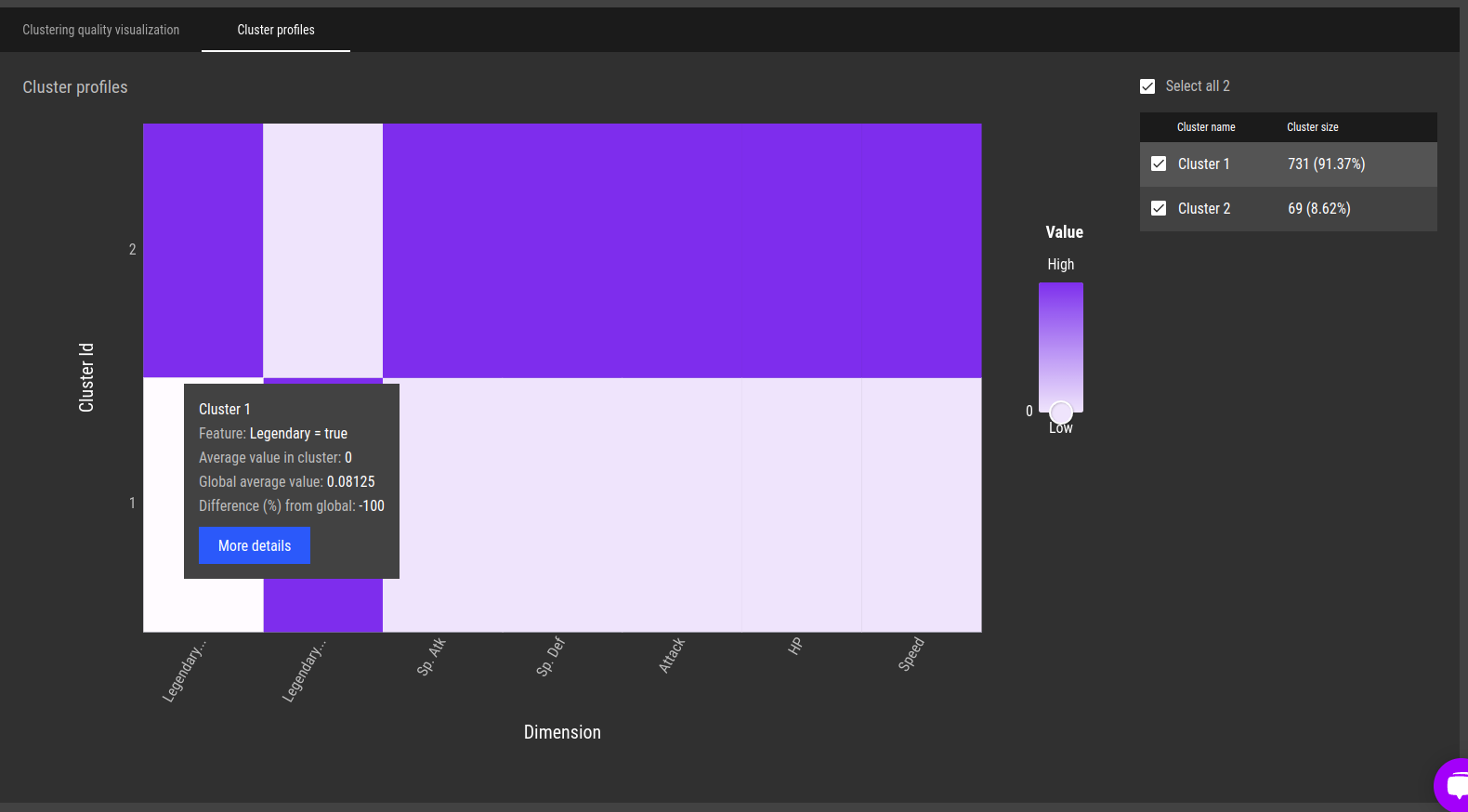 Fig 15 - Clustering profiles. A high-level overview of the differences between the clusters
Fig 15 - Clustering profiles. A high-level overview of the differences between the clusters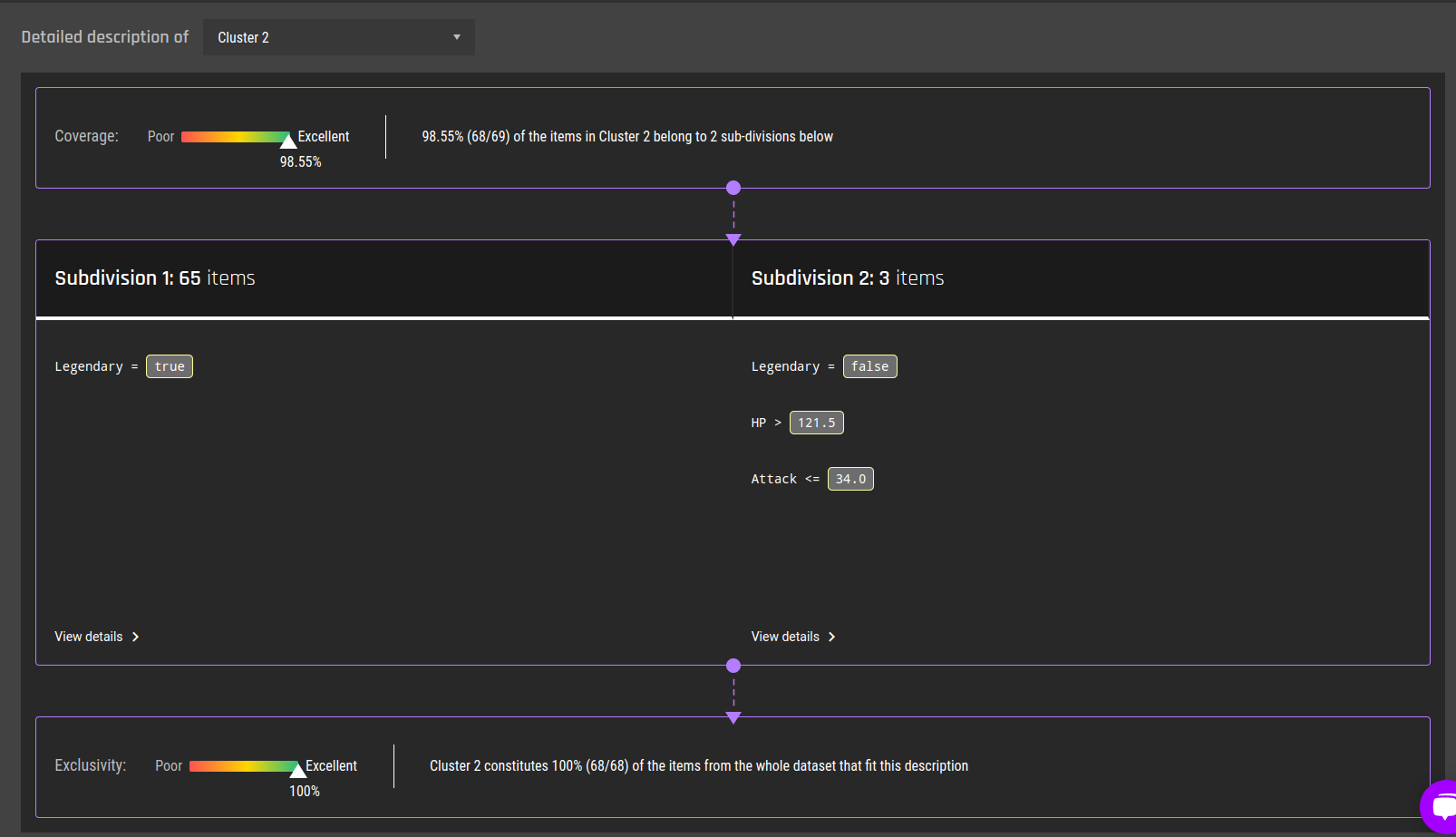 Fig 16 - Detailed description for cluster 2
Fig 16 - Detailed description for cluster 2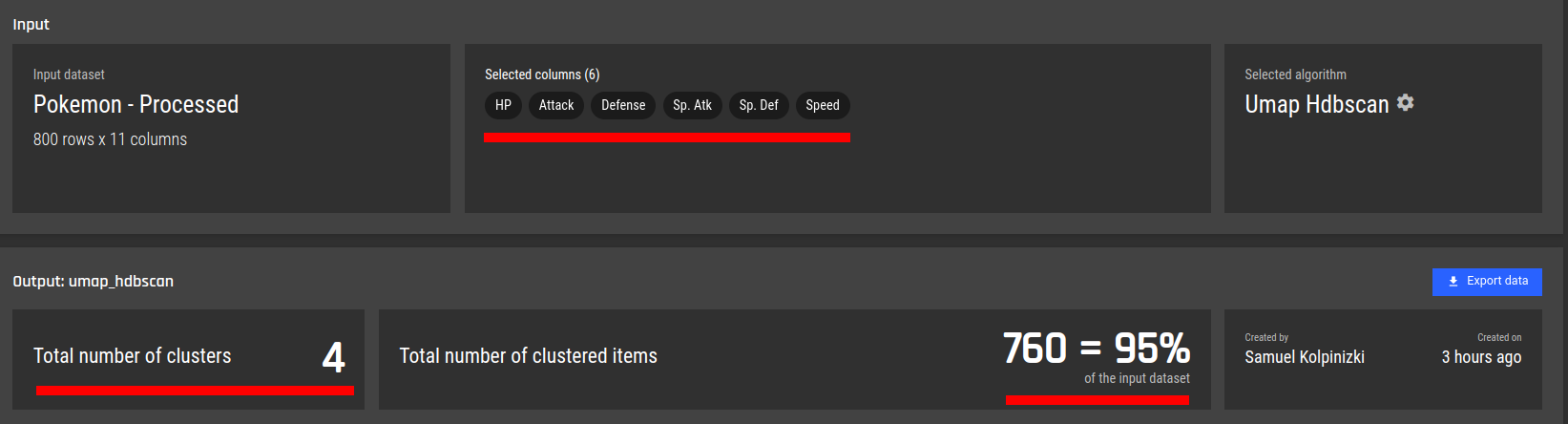
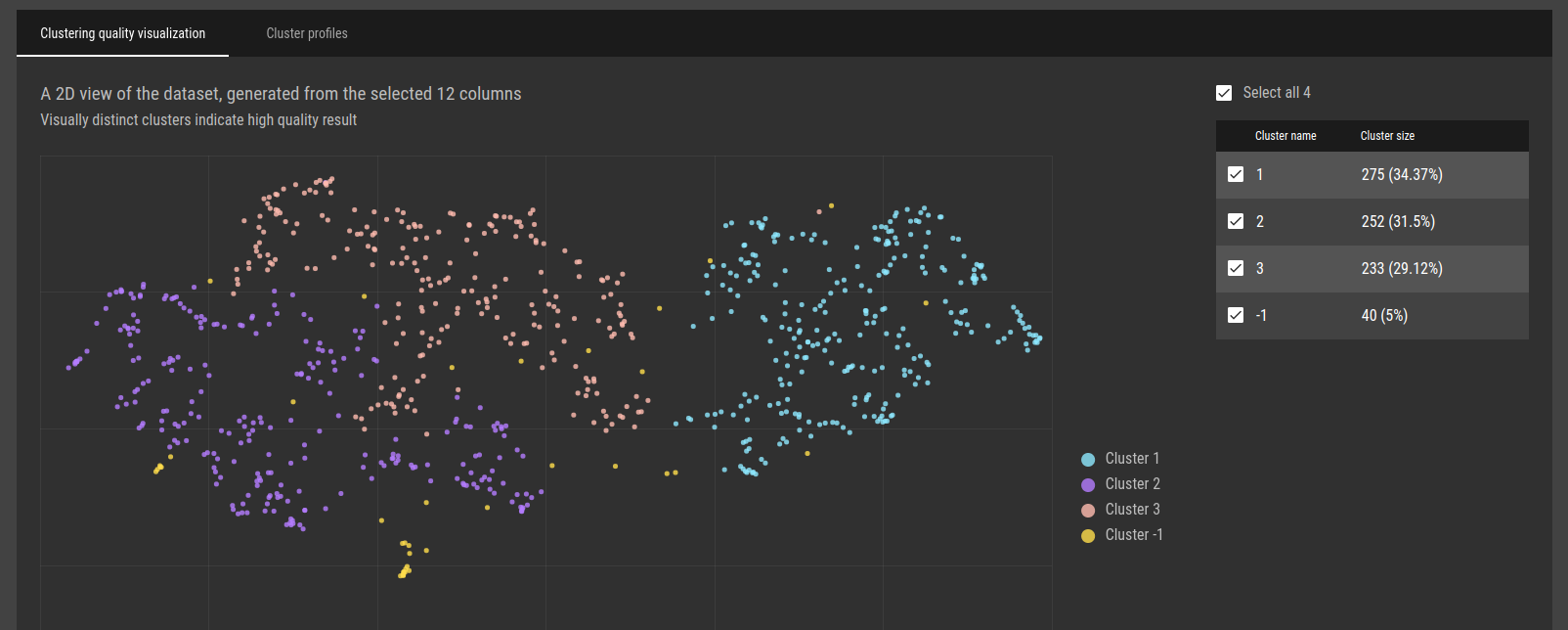 Fig 18 - Low dimensionality representation of records
Fig 18 - Low dimensionality representation of records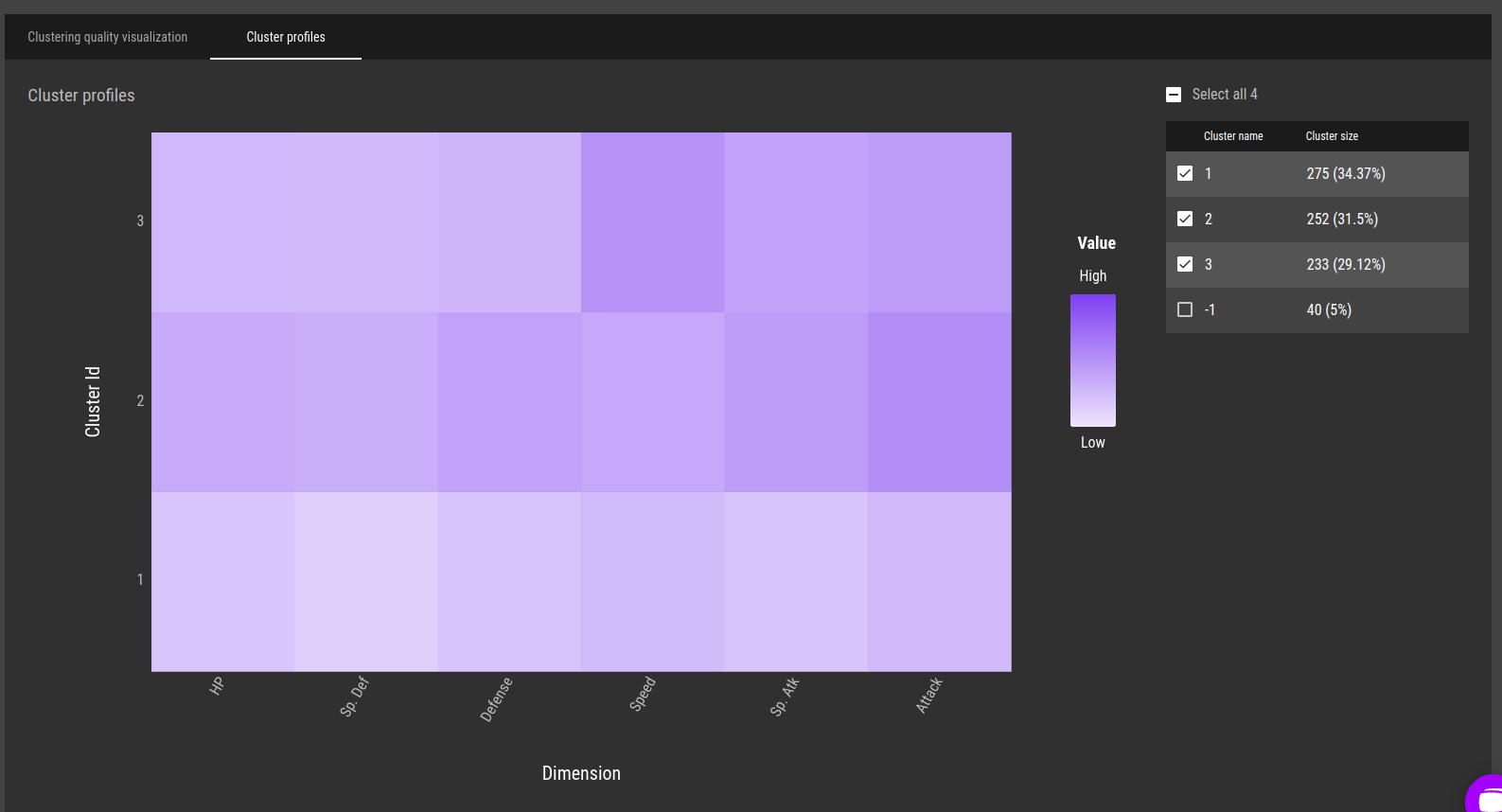
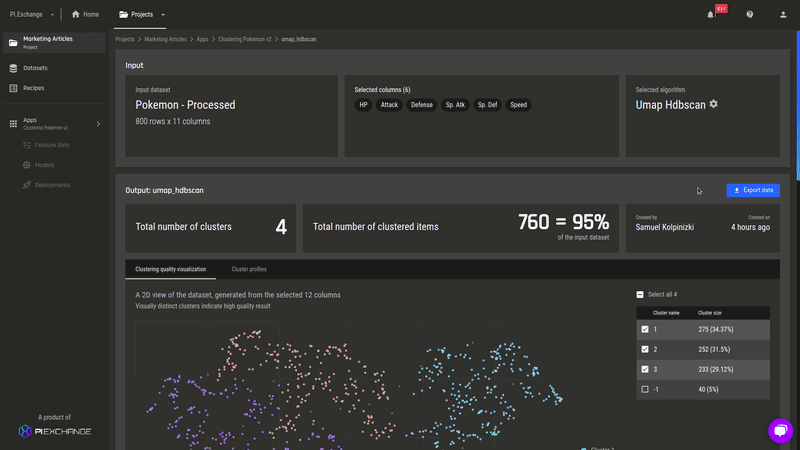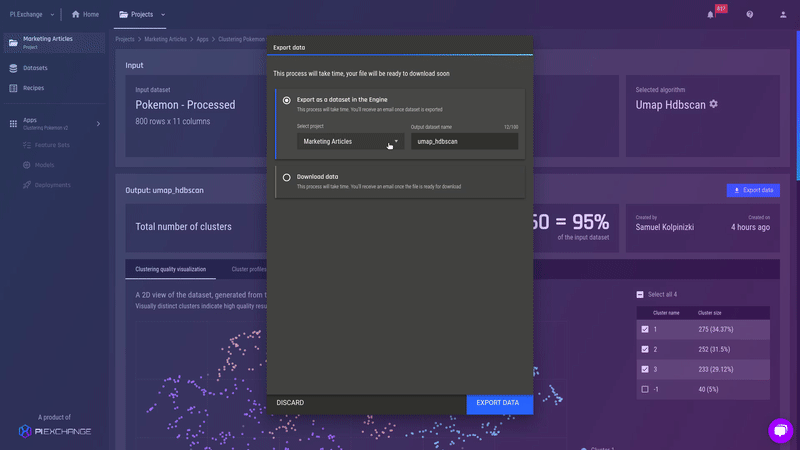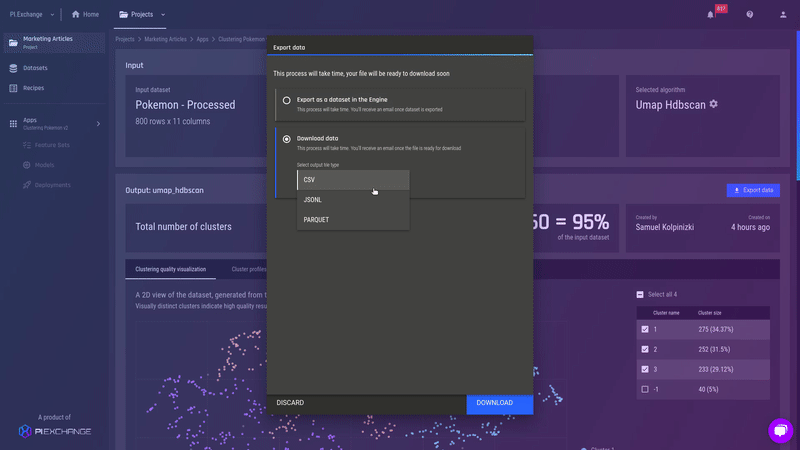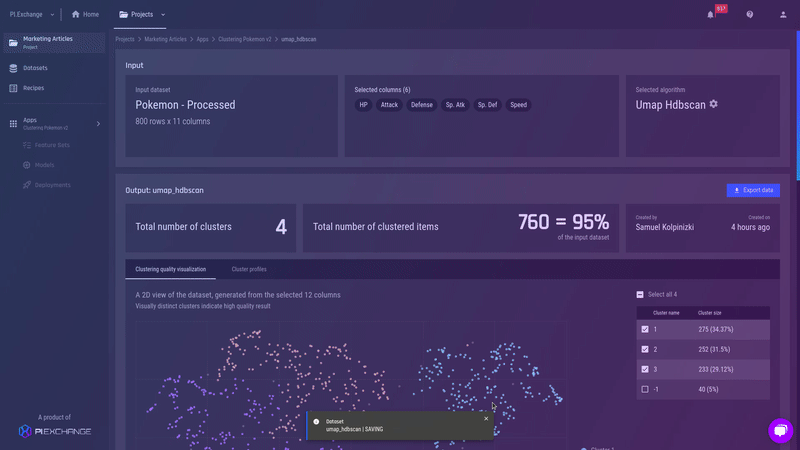
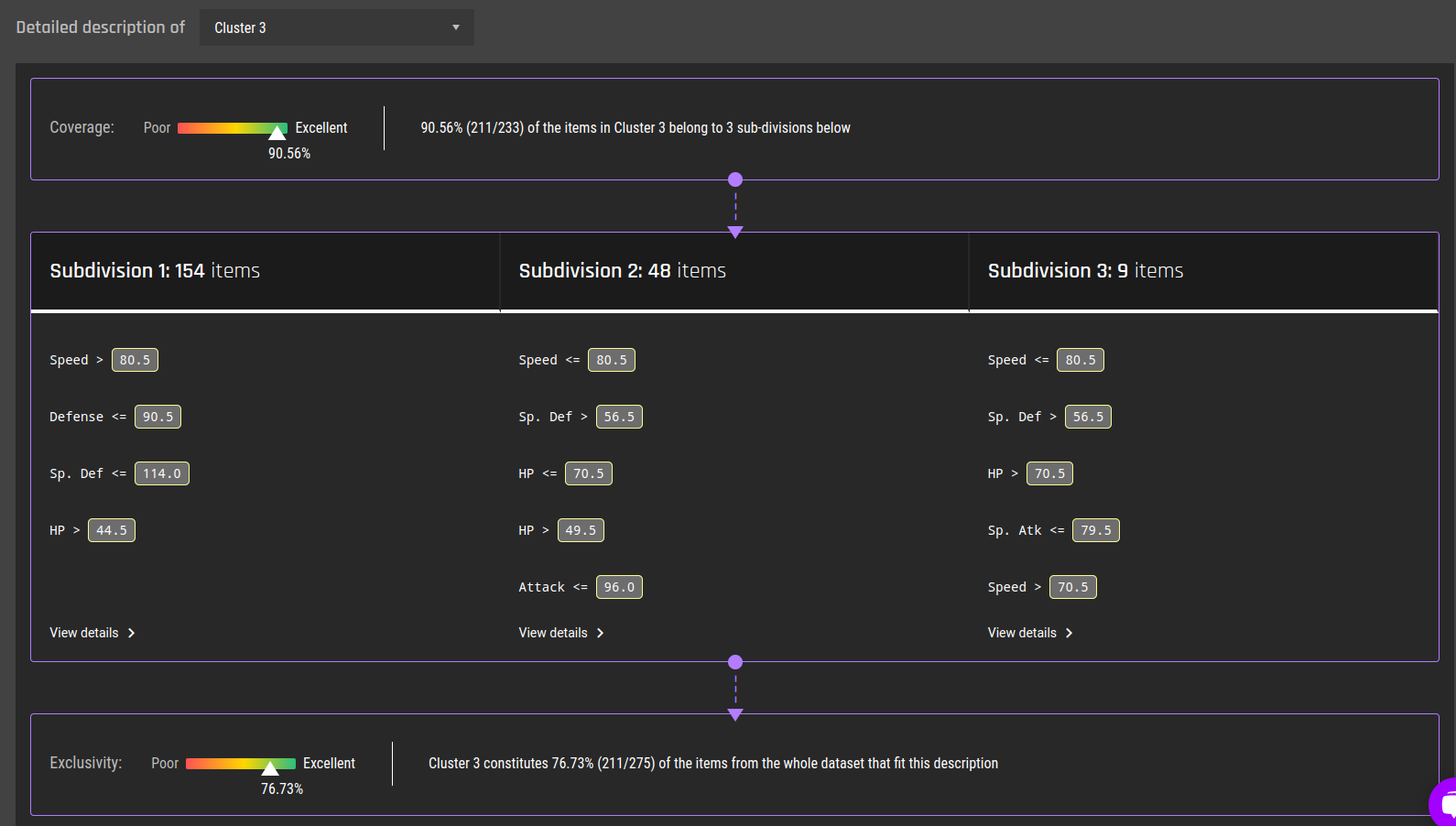
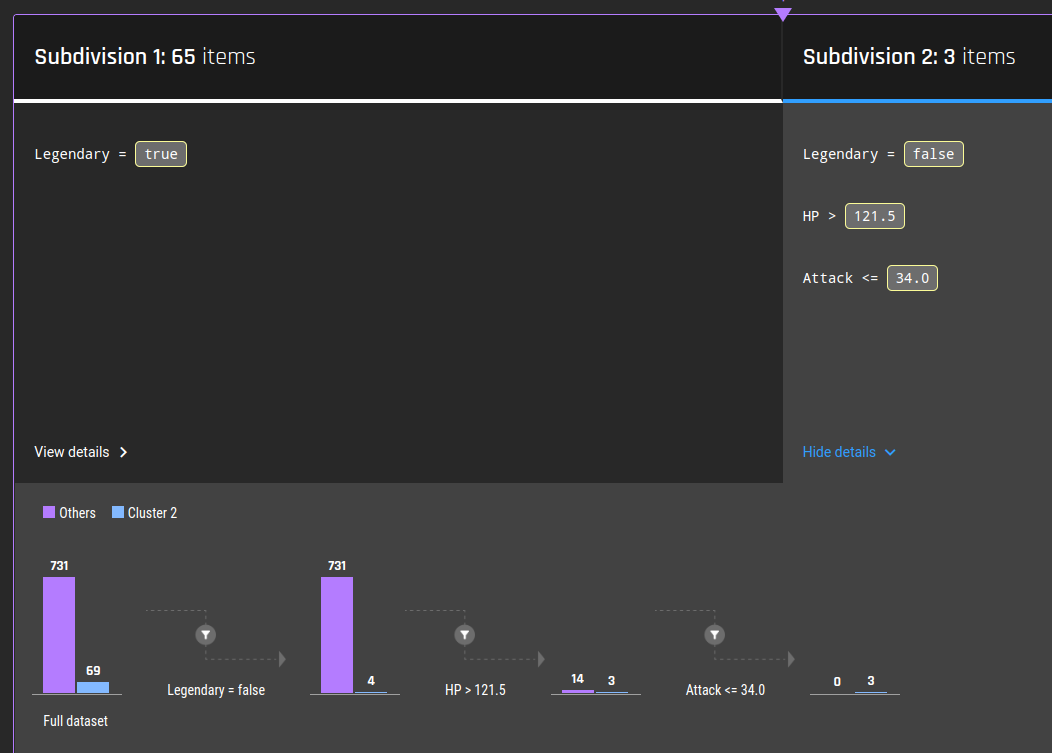 Fig 22 - Details of subdivision 2 for cluster 2
Fig 22 - Details of subdivision 2 for cluster 2
Getting Started with AI/ML
An Introduction to the Most Common Data Science Concepts and Terms
A list of the most commonly used machine learning and data science concepts and terms without any technical jargon to help you get started.