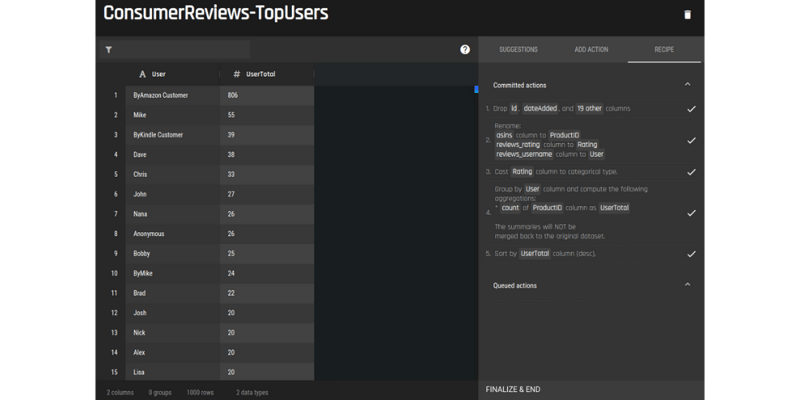
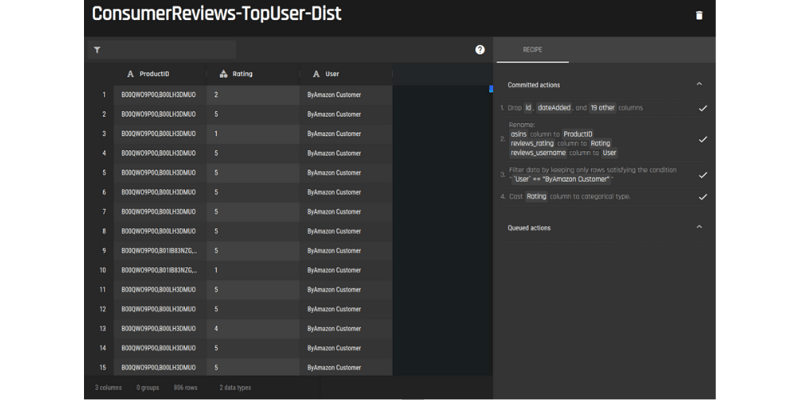
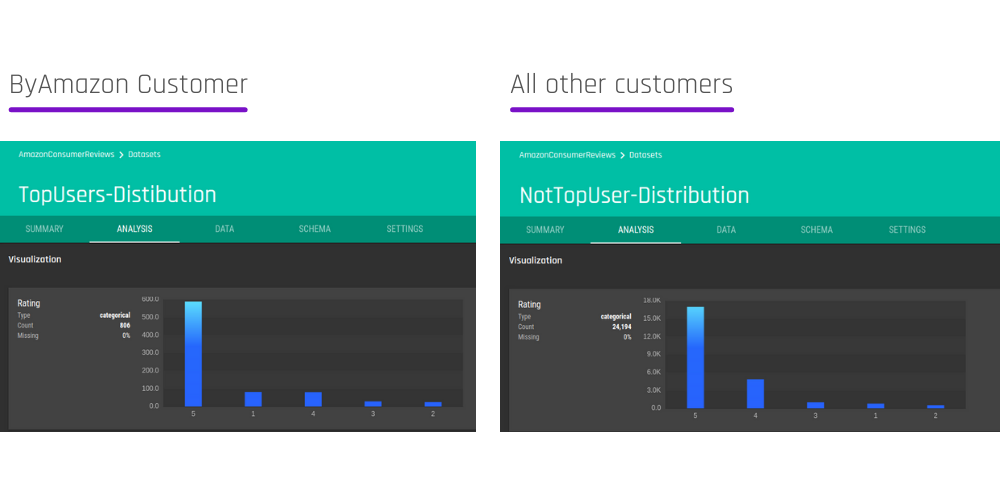

Data Preparation
Calculate your Net Promoter Score with the AI & Analytics Engine Pt. 2
Calculate your Net Promoter Score (NPS) with ease with the AI & Analytics Engine. Let us take you through the steps!